

Quando um APPLObjeto de aplicação interativa no JD Edwards usado para criar telas e interfaces de usuário. customizado do tipo Find/BrowseTipo de formulário padrão do JD Edwards projetado para pesquisar, filtrar e visualizar registros em uma lista. que consulta a F4211Tabela principal que armazena os detalhes das linhas de pedidos de venda no JD Edwards. ou F0911Tabela de detalhes do livro razão, onde são registradas todas as transações contábeis. leva mais do que alguns segundos para retornar as linhas no gridComponente de interface que exibe dados organizados em linhas e colunas, semelhante a uma planilha., os desenvolvedores imediatamente culpam a indexação do banco de dados ou a latência da rede. Na grande maioria das auditorias de performance que realizo, o gargalo é autoinfligido dentro do JDE. A correlação entre a performance de formulários de busca customizados JDE APPL e o design de business viewsCamada lógica que seleciona quais campos e tabelas serão disponibilizados para uma aplicação específica. é direta: unir dezenas de colunas desnecessárias em uma BSVW customizada força o banco de dados a realizar table scansOperação lenta onde o banco de dados lê todas as linhas de uma tabela para encontrar um resultado. dispendiosos em vez de index seeksOperação rápida onde o banco de dados usa um índice para localizar diretamente os registros desejados. limpos.
Para corrigir uma tela de busca lenta, não peça simplesmente ao seu DBAAdministrador de Banco de Dados, profissional responsável pela manutenção e performance dos dados. para criar outro índice composto customizado. Em vez disso, refatore a aplicação para alinhar os mapeamentos Grid Line-to-Business View com as chaves primárias existentes e audite o evento Grid Record is FetchedEvento disparado automaticamente pelo sistema cada vez que uma linha de dados é carregada no grid. em busca de loops ocultos de I/OEntrada e Saída; refere-se à comunicação entre o processador e o armazenamento de dados. nas tabelas F4101Tabela mestre de itens, contendo definições básicas de produtos e mercadorias. ou F0101Tabela mestre de endereços (Address Book), centralizando dados de pessoas e empresas.. Restringir sua BSVW customizada apenas aos campos essenciais (geralmente menos de uma dúzia) necessários para os critérios de busca e exibição inicial do grid pode reduzir os tempos de execução SQLLinguagem padrão usada para gerenciar e consultar dados em bancos de dados relacionais. em uma tabela com dezenas de milhões de linhas para menos de um quarto de segundo.
O Custo de Business Views Inchadas em Tabelas Grandes
Vamos observar o que acontece no banco de dados quando um desenvolvedor cria um formulário find/browse customizado usando uma business view padrão como a V4211A, ou uma customizada que traz todos os campos da tabela F4211 Sales Order Detail. O middleware de banco de dados do JDE (JDBMiddleware de banco de dados proprietário do JD Edwards que gerencia a tradução de comandos para o SQL.) gera uma instrução SELECT contendo cada coluna definida naquela business view, independentemente de esses campos estarem posicionados no formulário ou no grid. Para a F4211, que contém mais de cem colunas, esse padrão de design preguiçoso força o banco de dados a buscar e transmitir centenas de bytes de dados inúteis por linha, inflando o payloadVolume total de dados úteis transmitidos em uma transação de rede. da rede e desperdiçando a memória do buffer poolÁrea da memória RAM onde o banco de dados armazena dados lidos recentemente para acelerar acessos futuros. do banco de dados com dados que nunca serão exibidos ao usuário.
Para evitar esse overhead em formulários de busca de alto volume, os desenvolvedores devem construir uma business view dedicada e enxuta, contendo apenas o essencial. Isso significa selecionar apenas as chaves primárias (SDKCOO, SDDOCO, SDDCTO, SDLNID), os campos específicos usados como filtros de busca no cabeçalho e o punhado de colunas realmente renderizadas no grid. Reduzir uma business view de mais de cem colunas para uma ou duas dezenas pode reduzir drasticamente os tempos de execução SQL e diminuir significativamente o consumo de memória do servidor de aplicação, muitas vezes em até dois terços, durante sessões de usuários intensas.
Outro matador de performance comum é unir tabelas dentro da business view para exibir campos de descrição, como unir a F4211 à F4101 pelo short item number (SDITM). Se essas chaves de junção não estiverem devidamente alinhadas com os índices existentes no banco de dados, o otimizador do bancoSoftware interno do banco de dados que decide a estratégia mais eficiente para executar uma consulta. ignorará completamente o índice primário da F4211. Em vez de um rápido index range scanMétodo de busca que percorre um intervalo específico de valores dentro de um índice., o banco de dados executa um dispendioso nested loop ou hash join que dispara um full table scanLeitura completa de uma tabela, geralmente indicando falta de índices adequados para a consulta. em milhões de linhas de pedidos de vendas, transformando uma busca de sub-segundo em um congelamento do sistema de vários minutos.
Como o Mapeamento de Critérios de Busca Dita a Seleção de Índices
Quando um usuário clica em "Find" em um formulário Find/Browse, o servidor HTML do EnterpriseOneA linha principal de software ERP da JD Edwards, baseada em arquitetura web. traduz os campos de Form Control (FC)Elementos individuais de uma tela, como campos de texto, caixas de seleção e botões. mapeados como filtros em uma cláusula WHERE de SQL dinâmicoInstruções de banco de dados construídas pelo sistema no momento da execução, baseadas nos filtros do usuário.. Se sua aplicação customizada consulta uma tabela de alto volume como a F4211, que frequentemente excede vários milhões de linhas, o otimizador do banco de dados depende de que esses campos de filtro correspondam às estruturas de índice. Mapear um campo de filtro para uma coluna não indexada força o banco de dados a avaliar cada linha, transformando uma consulta de milissegundos em um dreno de sistema de vários segundos.
Buscas com caracteres curinga (wildcardCaracteres especiais, como o símbolo de porcentagem, usados para realizar buscas por partes de um texto.) irrestritas usando o sinal de porcentagem em colunas que carecem de indexação adequada causam severa degradação de performance. Quando um usuário insere um valor parcial em um campo de descrição não indexado, o mecanismo do banco de dados abandona os index range scans e recorre a um full table scan. Para evitar isso, os desenvolvedores devem configurar as propriedades do formulário para restringir o uso de wildcards em campos de busca de alto volume ou impor a entrada obrigatória em campos indexados.
Os desenvolvedores devem alinhar os controles de critérios de busca diretamente com as colunas principais dos índices primários ou secundários da tabela. Por exemplo, se você tem um índice secundário customizado na tabela Sales Order Detail (F4211) definido com Business Unit (MCU), Order Type (DCTO) e Line Number (LNID), os campos FC do formulário de busca devem ser apresentados exatamente nessa ordem hierárquica. Omitir a coluna MCU principal e filtrar apenas por DCTO torna o índice secundário inútil, pois o otimizador não pode realizar um index seek sem a coluna de chave mais à esquerda.
Configurar o operador de comparação no Form Design Aid é igualmente crítico. Selecionar um operador de comparação "Like" em vez de "Equal To" em campos numéricos, como o Short Item Number (ITM), impede que o otimizador do banco de dados execute index seeks precisos. O banco de dados é forçado a tratar o campo numérico como uma string de caracteres para avaliar o padrão, o que pode aumentar a utilização da CPU no servidor de banco de dados em quase metade durante as horas de pico.
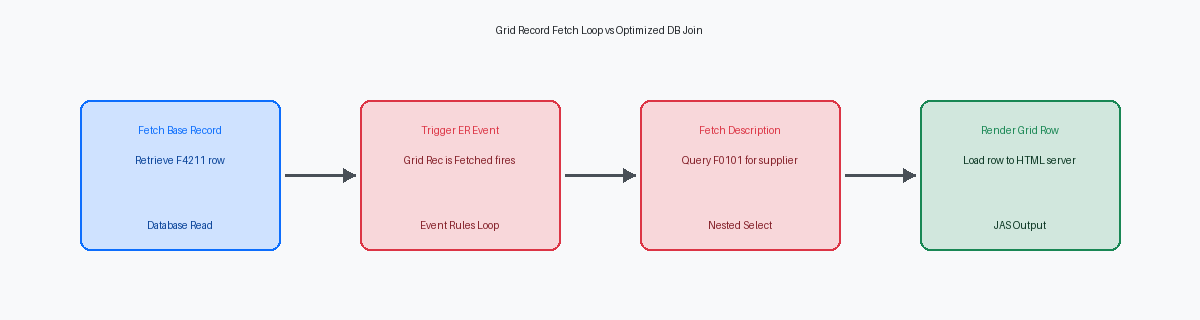
A Armadilha do Grid Rec is Fetched e Loops de Execução de ER
Colocar buscas no banco de dados ou complexas C business functionsMódulos de lógica de negócio escritos em linguagem C para garantir alta velocidade de processamento. dentro do evento Grid Record is Fetched é o erro arquitetural mais comum que vejo em aplicações Find/Browse customizadas. Os desenvolvedores frequentemente usam este evento para recuperar dados suplementares, como buscar um nome alfa na tabela Address Book Master (F0101) para cada linha. Se uma consulta de usuário retorna várias centenas de registros no grid, uma única business function de busca na F0101 dentro deste evento é executada centenas de vezes. O que parece uma chamada de banco de dados insignificante em nível de milissegundos durante o desenvolvimento local escala para um atraso composto de vários segundos em produção quando multiplicado por essas centenas de linhas.
Para eliminar este loop de execução, você deve transferir a carga de recuperação de dados de volta para o mecanismo de banco de dados ou para a memória. Em vez de executar chamadas seriais JDB_FetchFunção técnica de baixo nível usada para recuperar um registro específico do banco de dados. ou BSFN por linha, modifique a business view subjacente para unir as tabelas de descrição diretamente, como vincular a F4211 à F4101 para descrições de itens. Se uma junção direta de tabelas for impossível devido à lógica de negócio complexa, substitua os acessos ao banco de dados linha por linha por um padrão de cache em memóriaTécnica de armazenar dados na RAM para evitar consultas repetitivas e lentas ao disco.. O uso de funções de APIInterface de Programação de Aplicações; conjunto de funções que permitem a integração entre diferentes partes do sistema. de cache do JDE, como JDEDB_CreateCache e JDB_FindKey dentro de suas Event RulesLinguagem de programação visual do JD Edwards usada para definir o comportamento das aplicações., permite recuperar dados de referência uma única vez e realizar buscas em memória de alta velocidade.
Para formulários de busca de alto volume que processam milhares de linhas, a estratégia mais eficaz é desabilitar completamente o evento Grid Record is Fetched. Você pode pré-carregar dados mestres estáticos, como condições de pagamento ou centros de custo, em um cache de tempo de execução customizado durante o evento Post Dialog is Initialized. Ao consultar essas tabelas estáticas uma vez na inicialização do formulário, você pode preencher as colunas do grid usando buscas rápidas em memória em vez de disparar instruções SQL repetitivas. A implementação dessa mudança em um formulário de busca de ordens de serviço de alto uso normalmente reduz os tempos de carregamento da tela de vários segundos para frações de segundo.
Configuração de Carga do Grid: Page-at-a-Time vs. Load-All
Os grids padrão do JDE operam no modo Page-at-a-Time, buscando apenas de 10 a 50 registros para satisfazer os requisitos de exibição inicial. Esse comportamento padrão minimiza a pegada de memória no servidor HTML e mantém o tempo de execução SQL inicial abaixo de um quarto de segundo. Os problemas surgem quando os desenvolvedores ativam a propriedade Load All Grid Records para suportar ordenação no lado do cliente ou requisitos de exportação sem considerar o volume da tabela subjacente. Em um ambiente de produção onde a F4211 contém dezenas de milhões de linhas, uma configuração Load All sem filtros obrigatórios é um risco de estabilidade para o middleware.
Quando um usuário executa uma busca aberta em um grid Load All, o servidor JASJava Application Server; o servidor responsável por processar a interface web para os usuários. tenta construir todo o objeto do grid na memória antes de renderizar a resposta. Vemos consistentemente o esgotamento do heap da JVMÁrea de memória RAM reservada para a execução de aplicações Java no servidor. do JAS em aproximadamente 10.000 a 15.000 registros, dependendo da largura da business view e do número de colunas ocultas. Essa pressão de memória dispara ciclos agressivos de Garbage CollectionProcesso automático de limpeza da memória RAM para remover objetos que não estão mais em uso., aumentando a utilização da CPU no servidor web e, eventualmente, resultando em um 504 Gateway Timeout ou uma Web Client Exception para o usuário final.
Os desenvolvedores devem mitigar esse risco usando a função de sistema Set Max Rows Spoken dentro dos eventos Dialog is Initialized ou Find Button Clicked. Limitar o retorno em 500 ou 1.000 registros fornece dados suficientes para uso funcional, garantindo que o heap do JAS permaneça estável. Se a consulta exceder esse limite, o sistema para de buscar, evitando que o payload XMLLinguagem de marcação usada para formatar e trocar dados entre o navegador e o servidor. infle para um tamanho que o navegador ou o heap Java não consigam manipular.
A lógica de validação no evento Button Clicked deve bloquear explicitamente buscas onde campos de índice críticos como DCTO, KCO ou AN8 são deixados nulos. Ao verificar o status desses campos de filtro e usar a função Set Control Error, você força os usuários a fornecer critérios seletivos que o banco de dados pode realmente otimizar. Essa barreira arquitetural é mais eficaz do que qualquer governador de consulta em nível de banco de dados, pois interrompe o dreno de recursos na camada de aplicação, reduzindo a frequência de erros de "Out of Memory" do JAS em até 80% a 90% em ambientes de distribuição de alto volume.

Analisando a Execução SQL via Logs CallObject e JAS
Um formulário de busca que trava por dez segundos ou mais raramente é um erro de lógica de aplicação; é quase sempre uma instrução SQL não otimizada atingindo uma tabela com milhões de linhas como a F4211 ou F0911. Você não pode diagnosticar esses gargalos apenas pelo Form Design Aid (FDA) porque o middleware JDB abstrai a camada física do banco de dados. Você deve capturar o SQL bruto ativando o log CallObjectTipo de log que detalha a execução de funções de negócio e lógica no servidor Enterprise. (jdedebug.log) no fat client ou através do Server Manager para uma sessão web específica para ver exatamente o que está sendo solicitado ao banco de dados.
No jdedebug.log, procure pela string "SELECT ... FROM" seguida pela linha "OCI Execute" ou "SQL Execute". Isso fornece o tempo de execução da instrução SQL no jdedebug.log em microssegundos, permitindo identificar qual busca específica está paralisando a interface do usuário. Simultaneamente, os logs de debug do JAS permitem correlacionar a ação do usuário JDE a um ID de thread específico, garantindo que você não esteja perseguindo uma instrução fantasma de um UBEUniversal Batch Engine; motor responsável por executar relatórios e processamentos em lote em segundo plano. em segundo plano ou de uma sessão de usuário diferente.
Copie a instrução SQL literal do log — incluindo os marcadores de parâmetros — e execute um EXPLAIN PLANFerramenta de diagnóstico que revela como o banco de dados planeja executar uma consulta SQL específica. em seu estúdio de gerenciamento de banco de dados. É um equívoco comum pensar que o JDE sempre usa o índice definido na Business View (BSVW). Se o usuário filtrar em uma coluna não indexada no cabeçalho do grid, o otimizador do banco de dados pode adotar como padrão um full table scan, independentemente de como você pretendia que a busca se comportasse durante a fase de desenvolvimento.
A degradação de performance também decorre de instruções SQL de alta frequência e baixa duração que indicam loops aninhados. Se o log mostrar centenas de instruções SELECT idênticas atingindo a F0101 dentro de uma janela breve de alguns segundos, você provavelmente tem lógica no evento Grid Rec is Fetched realizando uma busca manual de dados mestres. Esse processamento linha por linha adiciona um overhead massivo à comunicação entre o servidor JAS e o Enterprise. Mover essas buscas para a junção inicial da BSVW ou usar uma C BSFN com um handle em cache pode reduzir essas centenas de viagens ao banco de dados para uma única execução.
Otimizar uma business view de um APPL customizado envolve mais do que selecionar colunas; requer um mergulho profundo no plano de execução SQL subjacente e na seleção de índices. Quando seu ambiente EnterpriseOne 9.2 é ajustado para alinhar o design da aplicação com as realidades do banco de dados, você elimina a latência que os usuários finais confundem com instabilidade do sistema.
