
Quando um grid customizado em uma aplicação como a P554210 leva mais de dez segundos para carregar 500 registros, as equipes de basis imediatamente culpam os índices do banco de dados ou o tamanho do heap da JVM do WebLogic. Na grande maioria das auditorias de performance realizadas no EnterpriseOne 9.2, a infraestrutura está perfeitamente bem; o gargalo são as Event Rules (ER) síncronas executadas no servidor JAS para cada linha. Alcançar tempos de resposta abaixo de um segundo exige parar de apontar o dedo para a infraestrutura e focar na otimização de performance de grid em APPL JD Edwards para grandes conjuntos de dados dentro do próprio motor de runtime do JDE.
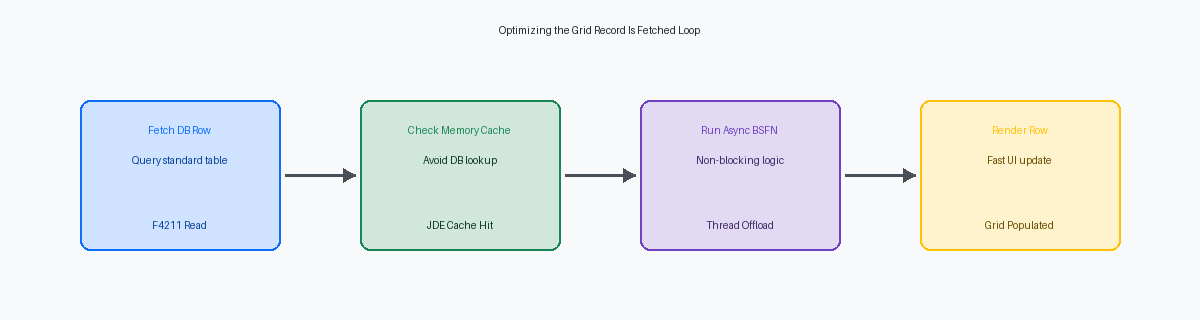
A otimização eficaz de grids depende da eliminação do overhead de roundtrips iterativos ao banco de dados e da execução síncrona de Business Function (BSFN). Ao mover a lógica pesada de validação do evento Grid Record Is Fetched para I/O de tabela assíncrono ou processamento em segundo plano, os desenvolvedores podem reduzir as chamadas ao banco de dados em 70% a 80%. Se sua equipe de desenvolvimento ainda está escrevendo loops de ER procedurais que buscam a mesma tabela de constantes para cada linha do grid, eles estão degradando severamente a experiência do usuário.
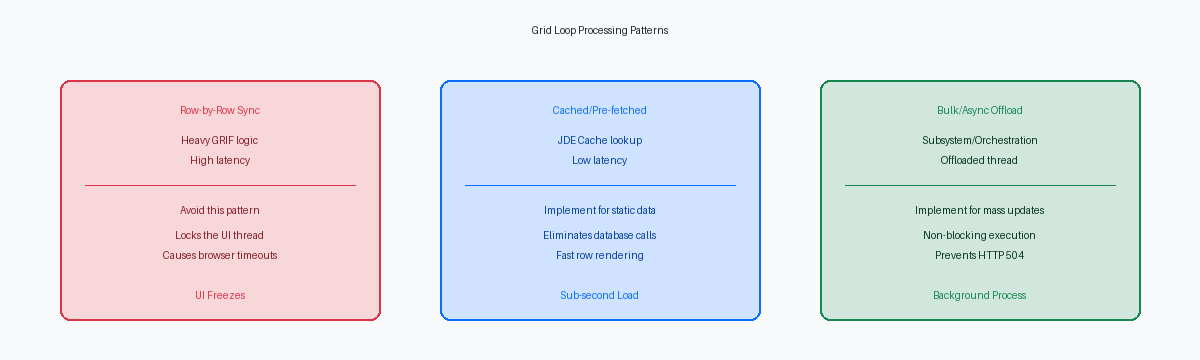
A Armadilha do Loop de Grid e a Execução Linha a Linha
Auditorias técnicas de APPLs customizadas frequentemente revelam centenas de linhas de Event Rules despejadas diretamente no evento Grid Record Is Fetched (GRIF). Este evento é disparado de forma síncrona para cada linha do banco de dados recuperada antes de ser renderizada na tela. Se um usuário consulta 500 linhas de pedidos de vendas em uma versão customizada da P4210, o motor JAS é forçado a executar todo esse bloco de ER 500 vezes consecutivas antes de apresentar os dados ao navegador.
A penalidade de performance aumenta quando os desenvolvedores colocam Master Business Functions pesadas ou BSFNs C customizadas como GetAuditInfo (B9800100) dentro deste loop. O que deveria ser uma busca SQL limpa de dois segundos degrada rapidamente para um congelamento do navegador de quase um minuto. Essa latência é causada por roundtrips constantes de rede entre o servidor HTML e o servidor de lógica Enterprise, já que cada linha individual exige sua própria serialização de ida e volta para executar a lógica de negócio.
Para resolver esse gargalo, mova a lógica de validação não essencial para fora do GRIF. Mudar a formatação visual para o evento Write Grid Line-Before garante que o JDE processe apenas as 10 a 20 linhas realmente visíveis no viewport da página atual do grid. Para cálculos pesados, executá-los de forma assíncrona ou adiá-los até que uma linha seja selecionada pode reduzir os tempos iniciais de carregamento de página em 75% a 80%.
Se você precisar calcular valores no fetch, configure as propriedades do grid para processamento "page-at-a-time" em vez de carregar todo o conjunto de registros. Essa alteração restringe a execução síncrona do GRIF ao tamanho da página ativa do grid, evitando que o cliente web trave em tabelas contendo dezenas de milhares de registros.

Otimizando a Seleção de Dados com Leituras Seletivas
Permitir que um usuário execute uma busca sem filtros em um formulário Find/Browse sobre uma tabela F4211 ou F0911 com milhões de linhas introduz riscos operacionais graves. A consulta SQL aberta resultante força o servidor JAS a alocar memória heap para centenas de milhares de linhas de grid, disparando um Java OutOfMemoryError e derrubando a sessão HTML ativa. Em uma auditoria técnica recente, resolvemos um problema onde algumas consultas abertas simultâneas na F4211 esgotaram a memória da JVM e derrubaram uma instância HTML inteira, interrompendo dezenas de usuários ativos.
Para evitar full table scans em tabelas que excedem vários milhões de linhas, os desenvolvedores devem impor pelo menos um campo de filtro indexado em formulários find/browse. Definir a propriedade "Filter Criteria" como "Equal" em uma coluna indexada como SDKCOO ou SDDOCO força o otimizador do banco de dados a executar um index seek em vez de um table scan dispendioso. Se o usuário deixar esses campos obrigatórios em branco, a aplicação deve bloquear programaticamente a consulta no evento "Button Clicked" do botão Find antes de atingir o banco de dados.
Quando filtros estáticos são insuficientes, o uso da função de sistema Set Selection dinamicamente na sequência de eventos "Clear Select" e "Set Selection" restringe a cláusula WHERE do SQL antes que o grid execute seu fetch primário. Crucialmente, as propriedades do grid devem ser configuradas para processamento "Page-at-a-Time" em vez de carregar todos os registros na memória de uma só vez. Isso limita a busca inicial do banco de dados ao tamanho da página do grid — normalmente 10 a 50 linhas — evitando o esgotamento de memória e mantendo tempos de resposta abaixo de um segundo.
O Custo de Chamadas Repetitivas de BSFN e Banco de Dados
A execução de uma única chamada de Business Function (BSFN) que leva insignificantes 10 milissegundos adiciona dez segundos de latência pura quando executada sequencialmente em um grid de 1.000 linhas. Esse acúmulo de latência ocorre frequentemente no evento Grid Record is Fetched, onde desenvolvedores rotineiramente colocam BSFNs padrão ou customizadas para buscar descrições auxiliares ou validar códigos por linha. A degradação de performance escala quando essas BSFNs dentro do loop abrem e fecham handles de tabela repetidamente, como chamar 'F0005 Get UDC' para recuperar descrições de User Defined Codes para cada linha.
Para eliminar milhares de operações redundantes de select no banco de dados, os desenvolvedores devem fazer o cache de dados de validação estáticos ou semi-estáticos em memória usando APIs de JDE Cache como jdeCacheInit durante o evento Dialog is Initialized antes do carregamento do grid. Em vez de atingir o banco de dados ou executar leituras na tabela F0005 milhares de vezes para um grande carregamento de grid, uma BSFN C customizada pode carregar os valores de UDC necessários ou registros de referência cruzada em um cache residente em memória uma única vez. Buscas em memória de sub-milissegundos substituem o I/O de disco e os saltos de rede, reduzindo o tempo de processamento por linha de 12 milissegundos para menos de um milissegundo.
Quando cálculos complexos são inevitáveis, mude da execução linha a linha para o processamento em lote (bulk processing). Passe arrays pré-carregados ou estruturas de dados contendo todos os campos-chave para uma Business Function C customizada em uma única chamada mapeada em memória, em vez de chamar a BSFN uma vez por linha do grid. Essa mudança estrutural permite que a BSFN realize uma única operação de abertura de banco de dados, execute buscas em lote, processe a lógica na RAM e retorne o conjunto de dados para a camada de aplicação. A implementação desse padrão em uma tela de disponibilidade de estoque de alto volume pode reduzir os tempos de transação em 80% a 85%, baixando o tempo de carregamento da tela de quinze segundos para menos de três segundos.
Manipulação do Grid Buffer e Pegada de Memória
Frequentemente analisamos ambientes de produção onde a JVM do servidor HTML trava com exceções OutOfMemoryError durante picos de expedição ou faturamento. O culpado é tipicamente um power form customizado ou um P42101 fortemente modificado contendo grids com mais de 100 colunas. Cada linha carregada nesses grids largos instancia um conjunto massivo de variáveis de grid buffer no heap de memória do JAS. Isso multiplica a pegada de memória quando cinquenta ou mais usuários simultâneos consultam grandes conjuntos de dados.
Os desenvolvedores agravam essa pressão de memória usando funções de sistema como 'Copy Grid Row To Grid Buffer' dentro dos eventos Grid Record Is Fetched ou Write Grid Line-Before. Esta função de sistema não apenas referencia a memória existente; ela duplica toda a estrutura de dados de 100 colunas dentro do heap de memória do JAS. Quando executada sequencialmente em um fetch de 1.000 linhas, essa alocação redundante dispara pausas agressivas de garbage collection da JVM que congelam o cliente web.
Um erro comum é ocultar colunas não utilizadas via Event Rules usando a função de sistema Set Grid Column Attribute. Ocultar uma coluna visualmente não impede que o servidor JAS busque, processe e especialize esses dados. Excluir essas colunas mortas do layout do grid inteiramente, em vez de ocultá-las via ER, reduz o tamanho do payload de serialização em mais da metade e estabiliza o perfil de memória do servidor web. Por exemplo, reduzir um grid de 120 colunas para os 20 campos realmente necessários reduz o overhead de memória por linha em cerca de 80%.
Lidando com Grandes Conjuntos de Dados com Processamento Assíncrono
Uma sessão web travada durante a gravação de um grid de 500 linhas é geralmente causada pela execução síncrona de lógica de validação pesada. Ao colocar uma BSFN de validação customizada nos eventos de grid "Row Exit & Changed - Asynchronous" ou "Row Is Selected", os desenvolvedores devem sinalizar explicitamente essa BSFN como assíncrona nas propriedades das Event Rules. Essa opção de configuração instrui o servidor HTML a devolver o controle para a camada de apresentação imediatamente, evitando que a interface do usuário trave enquanto o servidor enterprise processa a lógica de negócio em uma thread paralela.
Para processar cálculos pesados em um grid grande sem degradar a experiência do usuário, transfira a execução para o evento "Post Button Clicked" de um botão oculto. Em um APPL de alocação de estoque de um cliente de distribuição, substituímos os cálculos de grid inline por um sistema onde o botão "OK" grava as linhas modificadas em um cache de memória e, em seguida, clica programaticamente em um botão "Process" oculto. Executar a lógica de cálculo em lote no evento "Post Button Clicked" deste controle oculto garante que a thread principal do grid permaneça responsiva, evitando as armadilhas de processamento síncrono que disparam latência no navegador.
Quando um usuário tenta atualizar em massa mais de 200 linhas de grid simultaneamente, processar essas alterações dentro da thread interativa do APPL é um anti-padrão arquitetural. Uma abordagem mais eficiente é gravar os dados modificados do grid em uma tabela de staging customizada e disparar imediatamente um UBE de subsistema (como um driver customizado da série R55) ou chamar uma Orchestration baseada em AIS para processar o lote em segundo plano. Essa mudança mantém a thread de runtime interativa limpa e elimina os erros de timeout de gateway HTTP 504 que normalmente ocorrem quando o WebLogic ou um balanceador de carga F5 encerra uma conexão após seu limite padrão de 120 segundos.
Ferramentas de Diagnóstico para Identificar Gargalos no Grid
Administradores de banco de dados frequentemente apresentam um plano de execução SQL de sub-milissegundos para provar a saúde do banco, mas um grid padrão como P42101 ou P4312 ainda pode levar mais de dez segundos para renderizar 200 linhas. Essa desconexão ocorre porque as métricas de nível de banco de dados ignoram a latência da camada de aplicação introduzida pela execução das Event Rules (ER). Quando a ER é executada em eventos como Grid Record Is Fetched, o tempo gasto processando atribuições de variáveis e I/O de tabela ocorre inteiramente fora da visão do motor do banco de dados.
Isole essa latência correlacionando o jas.log com uma análise de call stack direcionada no jdedebug.log no Enterprise Server. O jas.log captura o timestamp preciso de quando o servidor HTML solicita os dados do grid, enquanto o jdedebug.log rastreia o custo exato em milissegundos de cada execução de BSFN disparada pela ER. A análise desses logs revela o overhead cumulativo de centenas de buscas sequenciais na F4101 ocorrendo por linha do grid.
Use o Performance Monitor dentro do Server Manager para rastrear os roundtrips entre o JAS e o Enterprise Server. Esta ferramenta expõe o volume de saltos de rede gerados por chamadas excessivas de BSFN a partir da camada de apresentação. Se um único carregamento de grid de 100 linhas resulta em centenas de roundtrips, você tem um indicador claro de que a lógica pertence a uma Business Function C consolidada, em vez de linhas individuais de ER.
Finalmente, use o Event Rules Debugger para percorrer os loops do grid e observar os estados das variáveis em tempo real. Isso permite capturar erros de lógica condicional que causam loops infinitos ou buscas redundantes dos mesmos registros de dados mestres. Esse rastreamento prático é a maneira mais direta de verificar por que um grid está executando dezenas de leituras desnecessárias no banco de dados para uma única linha.
Otimizar a performance do grid em um ambiente 9.2.x é apenas uma camada da pilha; os gargalos muitas vezes residem em uma gestão ineficiente de cache de BSFN ou planos de execução SQL não otimizados. Se suas aplicações customizadas estão lentas, isolar essas ineficiências na camada de aplicação é o primeiro passo para restaurar a estabilidade do sistema e a produtividade do usuário.
Para assistência na auditoria de suas aplicações EnterpriseOne customizadas ou na otimização da performance do seu servidor JAS, entre em contato com nossa equipe de consultoria ERP enterprise para agendar uma revisão técnica.
