

Muitas business functions (BSFNs)Funções de negócio do JD Edwards escritas em C ou Java para executar lógica no servidor. em C customizadas em instalações legadas do JDEJD Edwards EnterpriseOne, um sistema de gestão empresarial (ERP) da Oracle. são monólitos de milhares de linhas impossíveis de manter, onde a lógica de validação, as consultas em cache de memória e o Table I/OOperações de entrada e saída de dados diretamente nas tabelas do banco de dados. direto estão irremediavelmente emaranhados. Quando o volume de transações aumenta — como um lote de dezenas de milhares de linhas de pedidos de vendas EDIIntercâmbio Eletrônico de Dados, um padrão para transferência eletrônica de documentos entre empresas. atingindo a pilha de chamadas simultaneamente — essa falta de arquitetura causa bloqueios severos no banco de dados, vazamentos de memória e falhas no kernelProcesso central do servidor que gerencia a execução de tarefas e comunicações do sistema. corporativo.
Este guia fornece um exemplo prático de desenvolvimento de BSFN JDE para validar a lógica de negócios em C, demonstrando como isolar rotinas de validação voláteis do estado persistente do banco de dados. Ao desacoplar de forma limpa as consultas de cache de memória usando as APIsConjunto de definições e protocolos que permitem a comunicação entre diferentes componentes de software. nativas jdeCache das atualizações de tabelas físicas, você pode reduzir significativamente as idas e vindas ao banco de dados, muitas vezes em mais de três quartos, e eliminar rollbacksOperação que reverte o banco de dados para um estado anterior, cancelando alterações não finalizadas. de transação sob pesadas cargas de trabalho.
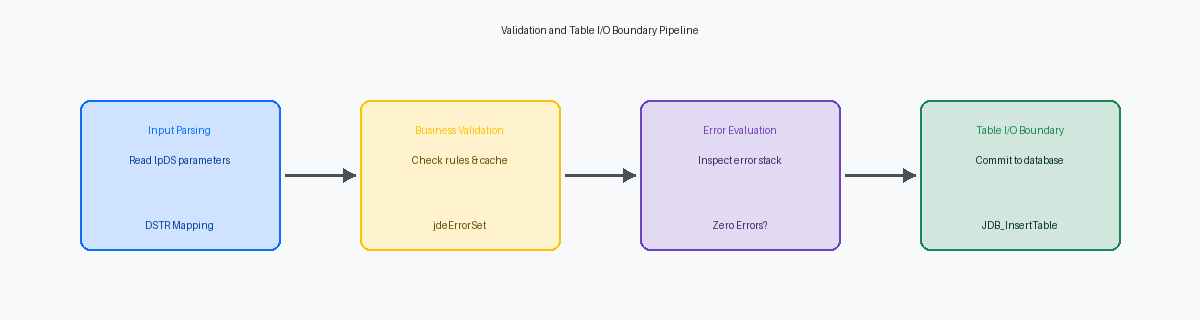
Projetando a Estrutura de Dados da BSFN para Validação
Em mais de duas décadas revisando business functions em C customizadas, arquitetos corporativos frequentemente encontram desenvolvedores despejando dezenas de campos desorganizados da tabela F4101Tabela mestre de itens no JD Edwards que armazena informações básicas de produtos. Item Master diretamente em uma única Estrutura de Dados (DSTR)Definição de parâmetros de entrada e saída que permite a passagem de dados para uma função.. Esse padrão de design garante dores de cabeça na manutenção e gargalos de desempenho durante o processamento em lote de alto volume em UBEsProcessos em lote (Universal Batch Engine) usados para relatórios e processamentos massivos de dados. como o R41110A. Uma DSTR de validação bem projetada deve segregar claramente os sinalizadores de controle de entrada, valores de negócio como LITM ou MCU e campos de status de saída para manter uma pegada de memória previsível.
Para evitar corrupção de memória e truncamento silencioso de dados dentro do código C, você deve impor o uso de itens padrão do Data DictionaryRepositório central que define todos os campos, tipos de dados e validações do sistema JDE., como EV01Item de dados padrão usado para representar valores booleanos ou sinalizadores de Sim/Não. para sinalizadores booleanos e ERRC para indicadores de erro. Passar um campo de caractere customizado em vez de EV01 pode levar a incompatibilidades de alinhamento quando o mecanismo JDE mapeia o buffer do middleware para o ponteiro lpDS. Restringir os sinalizadores de controle a EV01 e ERRC garante que o compilador alinhe corretamente os membros da estrutura em limites de 4 bytes.
Projetar a DSTR com um parâmetro de código de ação dedicado (usando o item de DD ACTION, onde '1' representa Validar e '2' representa Gravar) permite que uma única BSFN manipule a validação interativa de várias passagens em aplicações como o P4101. Durante os eventos iniciais de controle de saída e alteração, o APPL passa '1' para executar a validação de baixo custo sem confirmar registros no banco de dados. Assim que o usuário clica em OK, a mesma BSFN é invocada com o código de ação '2' para executar a inserção final dentro da transação.
Cada parâmetro nesta DSTR deve mapear diretamente para a struct typedef correspondente gerada pelo Object Management Workbench (OMW)Ferramenta de desenvolvimento do JDE para gerenciar objetos e o ciclo de vida do software. dentro do arquivo de cabeçalho da BSFN. Ao modificar uma DSTR, regenere este cabeçalho imediatamente para evitar deslocamentos de ponteiro quando o compilador C compilar a DLLBiblioteca de vínculo dinâmico que contém código executável compartilhado por vários programas.. Documentar a direção de cada membro da struct (IN, OUT, BOTH) dentro deste cabeçalho garante que os desenvolvedores não sobrescrevam inadvertidamente valores de entrada somente leitura.
Implementando o Padrão de Validação em C e APIs de Erro
Em business functions customizadas como a B5501001, os desenvolvedores frequentemente falham em vincular falhas de validação diretamente aos controles de formulário interativos, deixando os usuários olhando para telas em branco sem indicação do que falhou. O framework padrão de tratamento de erros do EnterpriseOne resolve isso baseando-se na API jdeErrorSet para associar códigos de erro específicos do Data Dictionary a controles de tempo de execução. Ao escrever código C, você deve passar o item de DD exato, como 0002 (Registro Inválido) ou 4115 (Status do Lote Inválido), garantindo que o cliente HTML destaque a coluna da grade ou o campo do formulário ofensivo em vermelho.
Para que esse mapeamento funcione, passar a estrutura lpBhvrCom — o ponteiro para as especificações de comportamento comum — é obrigatório. Sem esse ponteiro, o mecanismo de tempo de execução não pode propagar o erro para o contêiner APPL interativo ou registrar a falha dentro de um processo em lote de UBE. Em uma atualização recente da versão 9.1 para a 9.2 para um distribuidor global, resolvemos dezenas de funções C customizadas onde os desenvolvedores haviam passado NULL em vez de lpBhvrCom, o que suprimia silenciosamente erros críticos de alocação de inventário durante a entrada de pedidos de vendas.
Um padrão de validação limpo dentro da B5501001 usa uma verificação lógica sequencial que aborta o processamento posterior no instante em que um erro de gravidade crítica é encontrado. Em vez de aninhar dez níveis de instruções if, você avalia cada regra de negócio sequencialmente, chama jdeErrorSet e retorna ER_ERROR imediatamente após uma falha. Codificar strings de mensagens de erro diretamente dentro do código-fonte C é um anti-padrão grave que quebra o suporte a vários idiomas e ignora o mecanismo centralizado do JDE. Sempre mapeie suas falhas de validação para itens definidos do Data Dictionary, o que garante que, quando a Oracle atualizar uma rotina de validação padrão, seu código customizado herde o comportamento atualizado do sistema sem exigir uma recompilação. Essa abordagem mantém a pegada do seu código customizado limpa e garante a compatibilidade com futuros Tools ReleasesAtualizações de infraestrutura tecnológica do JD Edwards, independentes das atualizações de regras de negócio..
Desacoplando Consultas de Cache de Transações de Banco de Dados
Consultar tabelas físicas como F4102 ou F41021 dentro de um loop de processamento de milhares de registros degrada o desempenho várias vezes em comparação com consultas em cache de memória. Ao validar registros de inventário em massa em business functions C customizadas, atingir o banco de dados repetidamente para os mesmos dados mestres é uma falha arquitetural comum. A alternativa padrão é utilizar APIs de Cache de Usuário do JDE, como jdeCacheInit e jdeCacheFetch, para carregar dados de referência uma vez na memória durante a inicialização.
Um design de validação limpo isola essas consultas baseadas em memória em funções auxiliares internas dedicadas dentro do arquivo de origem C, mantendo a lógica de negócios principal limpa. Criar um auxiliar localizado como Ixxxxxx_RetrieveItemCache mantém sua função JDEBFRTN primária focada em regras de negócio em vez de manipulação de ponteiros de cache. Essa separação de preocupações garante que, se você alterar a estrutura da chave do cache, a modificação ficará restrita a uma única função auxiliar.
Falhar no gerenciamento do ciclo de vida dessas alocações de memória introduz sérios riscos de estabilidade ao seu Enterprise Server. A terminação adequada do cache usando jdeCacheTerminate é crítica para evitar vazamentos de memória que eventualmente esgotam o heapRegião de memória usada para alocação dinâmica de dados durante a execução de um programa. e travam os kernels callObject. Em um ambiente de alto volume que processa dezenas de milhares de linhas de pedidos de vendas diariamente, um identificador de cache não liberado acionará uma condição de falta de memória em seu Enterprise Server em poucas horas, forçando uma reinicialização não planejada do serviço.
Para evitar conflitos de sessão simultâneos, configure seu cache com um nome exclusivo usando o número do job do usuário ou o ID da sessão. Isso evita que várias sessões HTML executando a mesma BSFN corrompam os dados de validação em cache umas das outras. No Tools Release 9.2.7, a implementação de caches com chave de sessão resolveu problemas intermitentes de bloqueio de registros que anteriormente bloqueavam uma parte significativa das transferências simultâneas de armazém, às vezes até quinze por cento.

Estabelecendo o Limite de Table I/O em BSFNs C
No processamento de transações de várias tabelas, particularmente ao atualizar registros críticos de inventário na tabela F41021 Inventory Master, misturar a lógica de validação com gravações no banco de dados causa corrupção de dados. Auditamos modificações customizadas de roteamento de recebimento onde o desenvolvedor gravava diretamente no banco de dados dentro de um loop, apenas para encontrar uma falha de validação no meio do lote. Esse padrão resulta em registros órfãos porque metade da transação foi confirmada. A regra deve ser absoluta: as gravações no banco de dados nunca devem ser executadas se qualquer etapa de validação tiver registrado um erro na estrutura LPBHVRCOM.
Separar explicitamente as passagens de validação das passagens de gravação evita gravações parciais e órfãs no banco de dados em operações de várias tabelas. Isso significa iterar primeiro por toda a sua estrutura de dados de entrada ou cache, avaliar as regras de negócio e armazenar erros na memória antes de executar uma única linha de I/O. Se o seu loop de validação sinalizar até mesmo um erro, você sai da BSFN imediatamente. Essa separação limpa reduz a contenção do banco de dados, pois você evita manter bloqueios em tabelas como a F41021 enquanto espera que as rotinas de validação sejam concluídas.
Para tabelas customizadas, o uso das APIs JDB_OpenTable e JDB_InsertTable dentro de um limite de transação explícito garante a conformidade estrita com ACIDConjunto de propriedades (Atomicidade, Consistência, Isolamento, Durabilidade) que garantem transações de banco de dados confiáveis.. Você deve passar o identificador de sessão hUser da estrutura lpBhvrCom diretamente para essas APIs JDB para vinculá-las à transação ativa. Essa vinculação garante que, se a transação pai for revertida, as inserções em sua tabela customizada serão revertidas com ela.
Um erro comum é realizar atualizações de tabela dentro de um loop antes de verificar se todas as linhas de entrada no payload são completamente válidas. Em um grande upload de lote de faturas, executar uma atualização em uma das primeiras linhas enquanto uma linha subsequente contém um branch/plant inválido cria um subledger inconsistente. Valide todas as linhas antecipadamente e, somente quando a contagem de erros for zero, inicie o loop de transação para confirmar as alterações.
Um Exemplo Concreto de Código de Validação de BSFN C
Um ponto comum de falha em business functions C customizadas é a poluição da função de exportação principal com lógica de validação, o que ofusca o gerenciamento de memória e o tratamento de erros. Para evitar isso, o ponto de entrada principal da business function deve analisar a estrutura lpDS e inicializar as variáveis de estado interno com segurança antes de qualquer processamento começar. Delegar o trabalho pesado para uma função auxiliar interna, I5501001_ValidateAndWrite, atua como o orquestrador para manter a função de exportação principal clean e legível.
Dentro desta arquitetura, verificações explícitas de ponteiro nulo em tipos de dados JDE como MATH_NUMERICTipo de dado proprietário do JDE usado para cálculos matemáticos de alta precisão e escala. e JDEDATE evam violações de memória e falhas de sistema que podem derrubar um kernel callObject inteiro. Se você passar um ponteiro não alocado para FormatMathNumeric ou tentar comparar uma estrutura de data não inicializada, o kernel termina imediatamente. A implementação de uma validação rigorosa de ponteiros no limite de I5501001_ValidateAndWrite garante que sua lógica falhe graciosamente, retornando um erro estruturado para a pilha de chamadas em vez de um core dump.
A seguinte implementação demonstra essa segregação estrutural, mostrando como gerenciamos ponteiros estruturais, executamos verificações de erro e realizamos uma gravação em tabela condicional usando APIs nativas do JDE.
static JDEDB_RESULT I5501001_ValidateAndWrite(LPBHVRCOM lpBhvrCom, LPVOID lpVoid, LPDSD5501001 lpDS) {
HREQUEST hRequest = NULL;
JDEDB_RESULT jdDbResult = JDEDB_PASSED;
if (lpDS == NULL || &lpDS->mnAddressNumber == NULL || &lpDS->jdDateUpdated == NULL) {
return JDEDB_FAILED;
}
if (FormatMathNumeric(NULL, &lpDS->mnAddressNumber) != ID_SUCCESS) {
return JDEDB_FAILED;
}
if (lpDS->cActionCode == 'A') {
jdDbResult = JDB_OpenTable(lpBhvrCom->hEnv, _J("F5501001"), NULL, NULL, NULL, NULL, &hRequest);
if (jdDbResult == JDEDB_PASSED) {
/* Lógica de inserção executada apenas após validação bem-sucedida */
JDB_CloseTable(hRequest);
}
}
return jdDbResult;
}Depurando e Validando a Execução de BSFN C
As falhas de validação local em um fat client geralmente ocorrem porque os desenvolvedores confiam em pop-ups de tempo de execução padrão em vez de rastreamento de execução profundo. Para isolar uma falha de validação em seu código C customizado, anexe o depurador do Visual Studio diretamente ao processo active_run.exe ativo em seu cliente de desenvolvimento. Isso permite definir breakpoints dentro do diretório de origem (b9\DV920\source\B55VAL.c) e percorrer linha por linha a business function conforme o cliente web local aciona as regras de evento.
Confiar apenas na depuração interativa ignora o contexto transacional, e é por isso que você deve analisar o jdedebug.log para rastrear a sequência exata de chamadas de API e instruções SQL. Pesquise neste log pelas APIs JDB_OpenTable e JDB_Fetch para confirmar seus limites de consulta. Um JDB_ClearSelection mal posicionado pode causar uma passagem de validação silenciosa em um registro incorreto, o que é facilmente detectado em um arquivo de log de milhares de linhas se você filtrar pelos IDs de suas tabelas customizadas.
O código que funciona perfeitamente em um fat client local pode falhar catastroficamente sob carga em um servidor corporativo devido à corrupção de memória. Monitore os logs do kernel callObject em seu servidor HTML para identificar vazamentos de memória ou ponteiros não inicializados que só se manifestam em um ambiente multithread. Procure especificamente por erros COB0000012 ou terminações repentinas de kernel, que normalmente indicam que seu código C gravou além do tamanho alocado de uma estrutura de dados ou falhou ao liberar um ponteiro de memória alocado via jdeAlloc.
Para se afastar dos ciclos de teste manuais, automatize a validação de sua lógica de negócios em C usando o JD Edwards EnterpriseOne OrchestratorFerramenta do JDE para automação de processos, integrações e execução de serviços sem interface gráfica.. Executar a BSFN diretamente de uma solicitação de serviço customizada do Orchestrator ignora completamente o contêiner APPL. Isso permite que você execute suítes de testes de regressão com dezenas de variações distintas de payload em segundos, verificando se sua lógica de validação retorna consistentemente os códigos de erro corretos sem clicar manualmente em uma interface de Power Forms.
Se você estiver auditando seu código C customizado para eliminar vazamentos de memória ou melhorar o desempenho no Tools Release 9.2.8, nossa biblioteca de recursos inclui detalhamentos técnicos mais profundos sobre o gerenciamento de cache do JDE e operações de cache de usuário multithread. Entre em contato com nossa equipe de arquitetura corporativa para agendar uma revisão de código de suas business functions legadas.
