

Em nossas revisões de código em dezenas de ambientes JDE 9.2, descobrimos rotineiramente que uma parte significativa das funções de negócio C customizadas (BSFNsFunções de negócio no JD Edwards que executam lógica específica, escritas em C ou Event Rules.) — muitas vezes de um terço a metade — duplicam desnecessariamente a lógica padrão da Oracle. Os desenvolvedores frequentemente clonam módulos inteiros como B4200310 ou B1200010 apenas para executar uma única validação, em vez de implementar uma chamada limpa de exemplo jdeCallObjectAPI fundamental do JDE usada para chamar uma função de negócio a partir de um código C. JDE BSFN para executar uma função de negócio reutilizável. Esse código redundante quebra durante as atualizações porque ignora as atualizações de entrega contínua da Oracle. A abordagem mais limpa é chamar a função de negócio padrão dinamicamente a partir do seu código C customizado.
Implementar um padrão de execução dinâmica preciso usando jdeCallObject permite reutilizar funções de negócio padrão enquanto preserva totalmente os limites da transação e a pilha de erros lpBhvrComEstrutura que contém o contexto de execução, como informações do usuário e estado da transação.. Ao passar a estrutura comum de comportamento correta e mapear suas estruturas de dados dinamicamente, você evita codificar dependências de banco de dados que falham durante ESUsElectronic Software Updates são pacotes de correção ou melhorias entregues pela Oracle para o JD Edwards.. Essa abordagem garante que seu patrimônio customizado permaneça enxuto, tolerante a atualizações e compatível com o roteiro de suporte da Oracle até 2034.
O Custo de Duplicar a Lógica de Negócio Principal do JDE
Eu audito regularmente ambientes JDE corporativos contendo de 5.000 a 15.000 objetos customizados e descubro que entre 10% e 15% das funções de negócio C customizadas são clones desnecessários da lógica padrão. Os desenvolvedores costumam copiar e colar uma função C padrão em um objeto '55' customizado porque desejam ignorar uma única verificação de validação ou substituir um parâmetro codificado. Quando você duplica uma função de negócio mestra complexa como Sales Order Entry Edit Line (B4200310), você herda milhares de linhas de lógica altamente volátil que sua equipe deve agora ajustar manualmente durante cada ciclo de upgrade ou Electronic Software Update (ESUPacote de atualização de software eletrônico fornecido pela Oracle para corrigir bugs ou adicionar funcionalidades.).
Essa duplicação quebra o modelo de entrega contínua da Oracle. Em vez de clonar objetos padrão, invocar a função de negócio padrão diretamente usando a API nativa jdeCallObject garante que quaisquer correções de software críticas aplicadas pela Oracle se propaguem automaticamente para suas aplicações customizadas. Quando a Oracle entrega uma correção de cálculo de impostos ou um patch de alocação de inventário para o código padrão subjacente, seu wrapper customizado herda essa atualização imediatamente, eliminando completamente semanas de mesclagem de código manual e testes durante seu próximo upgrade de Tools ReleaseA camada de software base que fornece a infraestrutura tecnológica para as aplicações do JD Edwards funcionarem. 9.2.
Chamar diretamente BSFNs padrão existentes também preserva as rotinas de validação de banco de dados principais e garante a integridade transacional em tabelas padrão como F4211 e F0911. O B4200310, por exemplo, gerencia estruturas de memória interna complexas, cálculos de impostos e regras de precificação avançada antes de confirmar os registros. Ignorar essas rotinas nativas escrevendo inserts SQL customizados ou código C customizado simplificado inevitavelmente corrompe as transações downstream, levando a relatórios de integridade de razão corrompidos que as equipes financeiras devem reconciliar manualmente no final do mês.

Anatomia da API jdeCallObject e Estrutura LPBHID
Invocar diretamente uma função de negócio de dentro do código-fonte C requer contornar o mecanismo padrão de Event RulesLinguagem de programação visual do JD Edwards usada para criar lógica sem escrever código C. e fazer a interface direta com o mecanismo de tempo de execução principal do JDE. A API jdeCallObject é a porta de entrada para isso, exigindo exatamente quatro parâmetros primários passados em uma sequência rígida: a string do nome da função de destino (como "F4111EditLine"), o ponteiro de contexto de comportamento (lpBhvrCom), o ponteiro de perfil de usuário (lpVoid) e o ponteiro para a estrutura de dados de destino alocada na memória. Os desenvolvedores que transitam de Event Rules frequentemente subestimam o rigor dessa vinculação em nível C, onde passar um ponteiro de estrutura nulo ou incorretamente convertido dispara uma violação de memória imediata e um kernel zumbi no servidor corporativo.
O segundo parâmetro, lpBhvrCom, atua como o sistema nervoso operacional para a chamada. Esta estrutura de comportamento mantém dados vitais de estado ambiental, rastreando handles de conexão de banco de dados ativos, variáveis de sessão de usuário e limites críticos de processamento de transações manuais. Se você estiver executando um insert em várias tabelas no F0911 e F03B11 dentro de uma transação ativa, passar um ponteiro lpBhvrCom não inicializado ou corrompido quebra o limite da transação, fazendo com que o runtime confirme o primeiro insert enquanto falha silenciosamente no segundo.
Cada execução de jdeCallObject gera um código de retorno JDEDB_RESULTUm tipo de dado que representa o código de retorno de operações de banco de dados ou funções no JDE. explícito que deve ser capturado e avaliado. Um valor de retorno de ER_SUCCESS (0) indica execução bem-sucedida, enquanto ER_ERROR (2) ou ER_WARNING (1) sinaliza que a lógica de negócio falhou ao completar sua rotina. Ignorar a avaliação imediata desse código de retorno é um descuido comum e de alto risco em BSFNs C customizadas. Deixar de verificar ER_ERROR antes de prosseguir permite que o código downstream seja executado cegamente, gravando registros incompletos em tabelas como F4211 e corrompendo a integridade transacional de toda a thread do banco de dados.
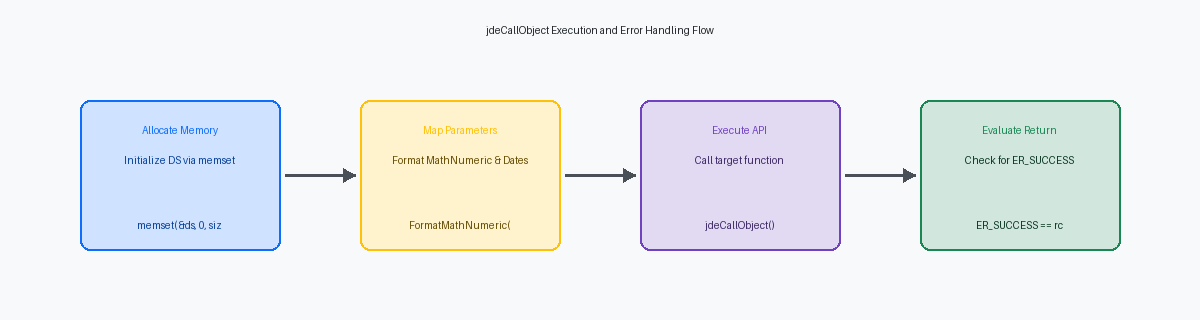
Alocação de Estrutura de Dados e Padrões de Mapeamento
A alocação de memória para a estrutura de dados de uma função de negócio de destino exige adesão estrita às regras de alinhamento, especialmente desde que o JDE migrou para o processamento de 64 bits com o Tools Release 9.2.5. Você deve alocar explicitamente essa memória usando variáveis de pilha para escopos locais menores ou alocação dinâmica de heap via API jdeAllocAPI do JDE usada para alocar memória dinamicamente durante a execução de um programa. ao lidar com arrays de tamanho variável ou ponteiros de longa duração. Ao usar a alocação de heap, o desalinhamento de uma estrutura MATH_NUMERICEstrutura de dados especial do JDE usada para lidar com cálculos matemáticos e precisão decimal. pode causar falhas de memória instantâneas em servidores corporativos Linux modernos.
Antes de passar este bloco de memória para jdeCallObject, você deve inicializar a estrutura de dados de destino com bytes nulos usando memset para apagar quaisquer valores de lixo da pilha. Ignorar esta etapa frequentemente introduz bugs intermitentes onde elementos não inicializados, como um campo de flag contendo lixo de memória aleatório, disparam falhas de validação falsas em funções de negócio mestras padrão como F4211 Edit Line (B4200310). Para evitar erros de incompatibilidade de tipo de compilação em seu compilador corporativo (seja Visual Studio ou gcc), sua BSFN chamadora customizada deve incluir explicitamente o arquivo de cabeçalho exato da função de destino, como b0100016.h para o MBF de Address Book.
Gerenciar o mapeamento de dados dentro dessas estruturas revela as limitações dos operadores C padrão, que não podem copiar tipos de dados JDE complexos. Tentar uma atribuição direta em uma estrutura MATH_NUMERIC ou JDEDATEFormato de data interno do JD Edwards usado para armazenar e manipular datas no banco de dados. corromperá os ponteiros internos e os valores de escala, levando à corrupção silenciosa do banco de dados. Em vez disso, você deve usar APIs dedicadas como FormatMathNumeric para converter valores numéricos em strings, ou ParseDate e DeformatDate para manipular campos de data com segurança. Para cópias diretas de estrutura para estrutura, dependa estritamente de MathCopy e FormatDate para preservar a integridade das posições decimais e estruturas internas antes de executar a chamada.
Implementação de Exemplo de Chamada jdeCallObject JDE BSFN
Codificar chamadas de funções de negócio mestras dentro de funções de negócio C customizadas é onde muitos desenvolvedores iniciantes falham, resultando em vazamentos de memória ou erros de ponteiros não mapeados. Uma implementação padrão e limpa chamando o Address Book Master MBFMaster Business Function: funções centrais que garantem a integridade dos dados ao processar transações principais. (B0100016) requer a declaração da estrutura de dados DSD0100016 diretamente em seu código C customizado, em vez de depender de ponteiros genéricos. Esta estrutura deve ser alocada na pilha para garantir a segurança de thread quando executada sob a arquitetura de kernel JDE CallObject, que lida com milhares de threads simultâneas em um ambiente HTML de produção típico.
Antes de invocar a API, você deve inicializar a estrutura com zeros usando memset para evitar que a memória de lixo corrompa o cache do JDE. Mapeie sua entrada de Address Number de destino para o membro dsD0100016.mnAddressNumber convertendo a string de entrada usando a API deformatMathNumeric, que analisa com segurança a string numérica no formato MATH_NUMERIC proprietário do JDE. Em seguida, você define explicitamente o campo de código de ação, dsD0100016.cActionCode, como 'Inquire' para disparar uma busca de leitura na tabela F0101.
Com a estrutura de dados preenchida, execute a chamada da API jdeCallObject passando a estrutura LPBHID, o nome da função de destino 'F0101GetAddressBookData' e um ponteiro para sua estrutura DSD0100016 inicializada. Avaliar o código de retorno não é negociável; você deve verificar se a API retorna ER_SUCCESS ou ER_ERROR. Ignorar esta validação é o principal motivo pelo qual ocorrem falhas silenciosas, deixando aplicações customizadas com campos de tela em branco enquanto os logs do kernel se enchem de exceções não tratadas.
Se a API retornar ER_ERROR, não deixe a falha morrer na camada C. Extraia o código de erro específico da pilha de erros do JDE usando a API jdeErrorSet para borbulhar a mensagem até o nível da aplicação interativa ou UBEUniversal Batch Engine: o motor responsável por executar relatórios e processos em lote (batch) no JD Edwards.. Isso garante que o usuário final veja o erro exato "Address Number Invalid" ou "Search Type Mismatch" em sua tela, em vez de uma exceção genérica e inútil do cliente web.
Gerenciando Limites de Transação e Pilhas de Erros
Um ponto de falha comum em interfaces financeiras customizadas é a criação de transações GL órfãs devido a conexões de banco de dados isoladas. Ao executar atualizações transacionais como Journal Entry Edit Line (B0900011), a BSFN filha deve se unir ao limite de transação ativa da função pai. Se você executar o B0900011 fora da transação do pai, uma falha subsequente nas etapas de processamento de voucher ou fatura deixa registros F0911 não confirmados ou saldos incompatíveis na tabela F0902. Você deve configurar o relacionamento pai-filho para que eles compartilhem uma única transação de banco de dados, garantindo que tudo seja confirmado ou tudo seja revertido.
Passar o handle do usuário ativo (lpBhvrCom->hUser) dentro da invocação jdeCallObject garante que bloqueios e deadlocks de banco de dados sejam evitados. Quando o runtime executa funções de negócio aninhadas, usar o ponteiro hUser do pai permite que o driver do banco de dados reconheça que as operações pertencem à mesma thread de sessão. Se você erroneamente alocar uma nova sessão de usuário via JDB_InitBhvr dentro da BSFN filha, o banco de dados a tratará como uma conexão separada. Esse erro leva ao bloqueio imediato da thread quando a filha tenta atualizar uma linha F0911 bloqueada pela transação não confirmada do pai.
Se uma execução filha falhar, você deve invocar as rotinas padrão de limpeza de cache ou rollback do JDE para evitar registros órfãos em tabelas como F0911. O uso do processamento de transação manual requer chamadas explícitas para APIs de commit ou rollback, dependendo do status final do código de retorno do jdeCallObject. Quando o jdeCallObject retorna ER_ERROR durante uma chamada ao B0900011, você deve chamar imediatamente o jdeCallObject para o B0900012 (Journal Entry Document Clean Up) para limpar o cache. Deixar de disparar essa limpeza deixa dados de cabeçalho e detalhes obsoletos nas estruturas de JDE cacheMecanismo de armazenamento temporário em memória para acesso rápido a dados durante o processamento de uma transação., o que corrompe a próxima transação processada na mesma thread do kernel call object.
Impacto no Desempenho e Gerenciamento de Cache Local
Executar um loop que processa mais de 10.000 registros em um UBE customizado — como um processador de edição/atualização de pedidos de vendas EDI de entrada — degradará severamente o rendimento do sistema se a função de destino realizar consultas redundantes ao banco de dados. Uma única consulta repetitiva ao F0010 ou F0101 dentro do loop adiciona latência cumulativa de execução SQL e de rede que pode transformar uma execução de minutos em um gargalo de várias horas. Essa sobrecarga é inteiramente evitável se você mudar de operações vinculadas a disco para operações vinculadas a memória.
Para otimizar o desempenho, os desenvolvedores devem contornar a E/S de disco repetitiva utilizando APIs de cache padrão do JDE, como jdeCacheInitAPI usada para inicializar um espaço de memória temporário (cache) para armazenar dados durante a execução., para armazenar e reutilizar dados de configuração estáticos em chamadas de funções filhas repetitivas. Carregar tabelas de constantes ou constantes de branch/plant em um cache de memória de usuário nomeado durante a fase de inicialização permite que o sistema resolva a lógica de validação instantaneamente. Recuperar um ponteiro da memória local leva menos de um microssegundo, enquanto consultar o banco de dados, mesmo com hits de índice, incorre em um round-trip de rede inevitável.
Outra área crítica de otimização é o gerenciamento de cursores e handles de banco de dados. Manter os handles das tabelas de banco de dados abertos em várias iterações, em vez de permitir que a BSFN chamada abra e feche handles em cada chamada, reduz significativamente a sobrecarga do cursor do banco de dados. Por exemplo, passar um ponteiro de tabela persistente ou manter o handle ativo em uma estrutura de dados pai evita que o sistema aloque e desaloca constantemente recursos do sistema operacional. Finalmente, você deve configurar as BSFNs chamadora e chamada para serem executadas exatamente na mesma thread do servidor corporativo. Esse alinhamento específico do OCMObject Configuration Manager: ferramenta que define onde os objetos e funções devem ser executados ou acessados. (OCM) evita que o kernel do JDE inicie comunicação entre processos ou atrasos de chamada de procedimento remoto, mantendo toda a pilha de execução local e rápida.
Dominar o jdeCallObject é a base para estabilizar um patrimônio de código customizado 9.2. Se você estiver otimizando o gerenciamento de memória ou depurando padrões de cache complexos, este site contém mergulhos profundos no uso de lpdsCommon e na eficiência da API jdeCache. Você também pode navegar pelo meu portfólio de projetos técnicos para ver como esses padrões de BSFN escalam em integrações OCIOracle Cloud Infrastructure: a plataforma de serviços de nuvem da Oracle onde o JD Edwards pode ser hospedado. de alto volume, processando dezenas de milhares de transações diariamente. Esses recursos técnicos focam nos 200–500 objetos verdadeiramente impactados que ditam a estabilidade e o desempenho do seu ambiente de produção.
