

Em um ambiente JDEJD Edwards EnterpriseOne, um sistema de gestão empresarial (ERP) da Oracle. corporativo típico, uma única tabela customizada como a F55101 frequentemente tem sua lógica de Select, Fetch, Insert e Update duplicada em 15 a 20 APPLsAplicações interativas do JD Edwards com as quais os usuários finais interagem através de telas. e UBEsUniversal Batch Engine; processos executados em lote no servidor, como relatórios ou processamentos massivos de dados. diferentes. Essa abordagem de copiar e colar Event Rules (ER)Linguagem de programação visual proprietária do JD Edwards usada para criar lógica de negócios nos objetos. cria um fardo de manutenção massivo; uma simples modificação no esquema do banco de dados — como adicionar um campo de código de categoria de 10 caracteres — força os desenvolvedores a refatorar e testar manualmente dezenas de objetos individuais. Adotar um padrão unificado de Table IOOperações de entrada e saída de dados, como leitura, inserção ou atualização em tabelas do banco de dados. em NERNamed Event Rule; um tipo de função de negócio que permite reutilizar lógica de programação em vários objetos. no JDE para evitar blocos de ER repetidos consolida essas operações de banco de dados em uma única Named Event Rule orientada por ação.
Ao encapsular todas as interações de banco de dados para uma tabela dentro de uma única NER, você reduz o volume de ER customizadas em até 30% a 50% e estabelece uma camada de acesso a dados limpa e modular diretamente no conjunto de ferramentas do JDE. Em vez de espalhar instruções brutas de Table I/O em projetos do Object Management Workbench (OMW)A ferramenta central do JD Edwards para gerenciar o desenvolvimento e o ciclo de vida de todos os objetos do sistema., os desenvolvedores chamam uma BSFNBusiness Function; módulos de código reutilizáveis que executam processamentos lógicos no servidor de aplicações. centralizada usando um parâmetro simples de código de ação (ex: 'A' para Add, 'U' para Update, 'F' para Fetch). Essa mudança reduz drasticamente o tempo de retrofit durante upgrades de Tools ReleaseA camada de software base que fornece a infraestrutura técnica e ferramentas para o funcionamento do JD Edwards. e garante a integridade absoluta dos dados em todos os pontos de entrada, desde aplicações interativas até payloads de AIS OrchestrationFerramenta que permite automatizar processos complexos e integrar o JD Edwards com sistemas externos via APIs REST..
O Custo de Table IO Disperso em Event Rules
Quando modificamos uma tabela customizada como a F55101 — por exemplo, adicionando um campo de centro de custo (MCU) de 10 caracteres ou uma data de auditoria — a dor de cabeça imediata não é a regeneração da tabela em si. O problema real é caçar as 10 a 15 diferentes aplicações interativas (APPLs) e relatórios em lote (UBEs) onde um desenvolvedor arrastou e soltou manualmente os blocos de Event Rules de Fetch, Select e Update. Duplicar o Table I/O nesses objetos cria uma pegada de manutenção exponencial, transformando uma atualização de esquema simples de duas horas em um exercício de busca e substituição de vários dias em seus projetos do Object Management Workbench (OMW).
Em um ambiente 9.2 padrão, uma tabela customizada como a F55101 frequentemente tem suas operações CRUDAcrônimo para Create, Read, Update e Delete; as quatro operações básicas de manipulação de dados em um sistema. copiadas e coladas em 10 a 15 pontos de entrada distintos, variando da tela de manutenção primária a UBEs de EDIElectronic Data Interchange; padrão para a troca eletrônica de documentos de negócios entre diferentes sistemas e empresas. customizados. Cada um desses blocos repetidos de Event Rules representa um ponto crítico de falha. Um desenvolvedor editando uma instrução Select ou Update em um relatório em lote customizado pode facilmente omitir um campo de índice chave como UKID ou LNID, levando a table scansOperação ineficiente onde o banco de dados percorre todas as linhas de uma tabela por falta de índices adequados. que degradam a performance do seu banco de dados Oracle ou SQL Server.
Essa arquitetura dispersa também paralisa sua capacidade de impor integridade de dados global ou log de auditoria consistente. Se sua empresa decidir registrar cada alteração nos campos de status da F55101 em uma tabela de auditoria customizada, você deve injetar manualmente essa lógica de log em múltiplos objetos chamadores individualmente. Se esquecer apenas uma tela interativa, sua trilha de auditoria de conformidade será quebrada. Para evitar isso, minha recomendação direta é isolar todas as interações de banco de dados para a F55101 em uma única business function dedicada antes do seu próximo upgrade de Tools Release.

Projetando uma NER Focada para Operações de Tabela
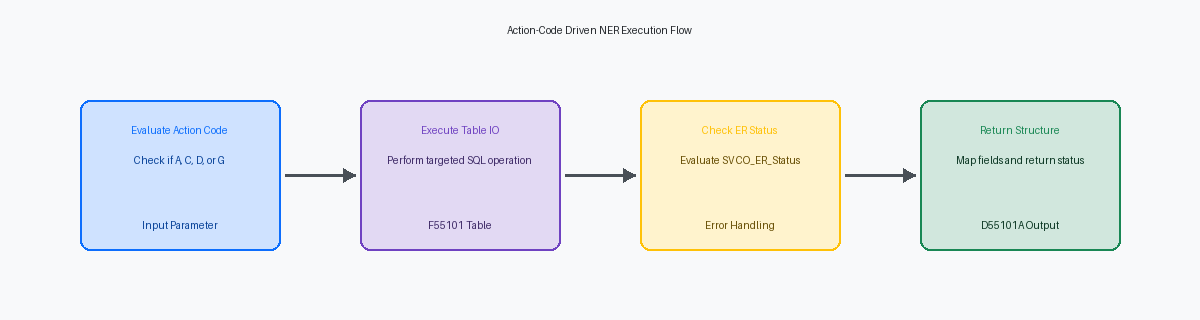
Em nossa remediação do sistema de entrada de pedidos customizado de um cliente de distribuição global, substituímos mais de cem instruções individuais de Table IO espalhadas por uma dúzia de aplicações diferentes por uma única Named Event Rule (NER) dedicada. A base desse padrão é uma estrutura de dados unificada, D55101A, que encapsula cada coluna da tabela de destino junto com parâmetros de controle críticos. Em vez de passar variáveis individuais por múltiplas camadas, essa estrutura agrupa os campos funcionais da tabela com flags de controle como Action Code (szActionCode) e Return Status (cReturnStatus).
Dentro da NER, uma estrutura condicional avalia o Action Code para determinar a operação do banco de dados. Impomos um padrão rigoroso: 'A' executa um Insert para adicionar um registro, 'C' realiza um Update para alterá-lo, 'D' executa um Delete e 'G' dispara um Fetch Single para obter os dados. Esse design impede que os desenvolvedores escrevam loops Select/Fetch ad-hoc e incompletos nas Event Rules da aplicação, forçando todas as interações de banco de dados através de um caminho de código previsível e testado.
Consolidar essas operações em uma única NER garante que as transações de banco de dados sejam gerenciadas como uma unidade de trabalho única e previsível, o que é crítico ao mapear para os limites de processamento de transações do EnterpriseOne. Se um insert falhar durante uma atualização de múltiplas tabelas, a NER pode reverter imediatamente a transação e retornar um status de falha '1' para o chamador, evitando registros órfãos em tabelas customizadas como a F55101. Essa camada de abstração isola completamente o layout físico da tabela das aplicações chamadoras. Se você adicionar uma nova coluna à tabela ou modificar um índice, você atualiza o código interno da NER e a estrutura de dados, deixando as Event Rules chamadoras intocadas e eliminando a necessidade de reconstruir dezenas de objetos APPL ou UBE.
Lidando com Table IO Complexo e Estados de Erro
Em mais de uma dúzia de auditorias de upgrade, vi NERs customizadas falharem silenciosamente porque os desenvolvedores assumiram que uma instrução Select sempre tinha sucesso. Sua lógica de avaliação de status de ER deve inspecionar SV CO_ER_Status imediatamente após cada instrução Fetch Single, Update ou Delete. Colocar até mesmo uma atribuição ou chamada de BSFN utilitária entre o Table IO e a verificação de status corre o risco de sobrescrever a variável de sistema, resultando em falsos positivos que poluem tabelas como a F41021 com dados corrompidos.
Em vez de codificar textos de glossário ou chamar Set ER Error dentro da NER, mapeie os estados do banco de dados para um parâmetro de saída padronizado como cReturnCode ('0' para sucesso, '1' para registro não encontrado, '2' para chave duplicada). Isso permite que a APPL ou UBE chamadora trate a falha graciosamente. Uma APPL de varejo pode interromper a transação, enquanto um UBE em lote noturno pode simplesmente registrar o aviso e prosseguir. Passar o código bruto para cima na pilha mantém a NER reutilizável em diferentes ambientes.
Ao lidar com buscas de chave parcial com um loop Select e Fetch Next, não validar o status de retorno do Select inicial é uma armadilha perigosa. Se o Select falhar e seu código entrar em um loop While controlado por SV CO_ER_Status is equal to CO SUCCESS, você pode disparar um loop infinito que trava a CPUCentral Processing Unit; o processador principal do servidor que executa as instruções do sistema. do servidor de enterprise na capacidade máxima. Sempre inicialize as variáveis de controle de loop e verifique explicitamente o status do primeiro Fetch Next antes de entrar no bloco.
Implementação Passo a Passo da NER de Table IO Customizada
Padronizar o acesso ao banco de dados em uma Named Event Rule (NER) customizada começa com um design rígido de estrutura de dados. Mapeamos as chaves primárias, os campos de payload e um Action Code de 1 caractere (cActionCode) para rotear a execução. Dentro da NER, a primeira linha de Event Rules deve ser um bloco de desvio condicional — tipicamente uma estrutura Select — que avalia este Action Code para rotear a execução. Esse roteamento centralizado garante que nenhuma chamada de banco de dados seja feita sem validar o tipo de operação primeiro, eliminando o risco de atualizações acidentais na tabela.
Quando o Action Code é 'G' (Get), a NER avalia os parâmetros de chave recebidos. Se o chamador passar uma chave única totalmente qualificada, o código executa um Fetch Single direto contra a tabela F55101; caso contrário, inicia uma sequência de cursor Open, Fetch e Close dependendo se uma chave única é fornecida. Quando o Action Code é 'A' (Add), a NER intercepta a operação de gravação para preencher centralmente os campos de auditoria padrão. Em vez de depender do chamador para passá-los, a NER atribui programaticamente o ID do usuário (USER), ID do programa (PID), data de atualização (UPMJ) e hora do dia (TDAY) antes de executar a instrução Insert.
Para uma operação 'C' (Change), a NER executa um Fetch for Update ou uma instrução Update direta com base nas chaves primárias passadas na estrutura de dados. Se o bloqueio otimista for necessário, o Fetch for Update bloqueia a linha no banco de dados F55101 antes de modificar o registro. Caso contrário, um update direto é executado, mapeando estritamente para as chaves primárias. Isso encapsula as durações de bloqueio do banco de dados em milissegundos, evitando os bloqueios de longa duração que ocorrem quando os desenvolvedores escrevem Table IO manual diretamente nas event rules de formulário.
Exemplos de Chamada: Refatorando Event Rules de APPL e UBE
Observe o evento Grid Record Is Validated em um clone customizado da P4210 padrão. Em uma implementação legada típica, este evento contém dezenas de linhas de Table I/O manual, espalhadas com instruções Fetch Single para validar registros de item branch. Ao refatorar essa lógica, comprimimos essas linhas de Event Rules redundantes em uma única e limpa chamada de BSFN passando os parâmetros de chave. Essa mudança reduz o tamanho das especificações locais da APPL e elimina o risco de handles de tabela não fechados durante a rolagem rápida da grade.
Essa abordagem de refatoração isola a camada de apresentação da aplicação interativa da camada de acesso ao banco de dados, imitando uma arquitetura Model-View-Controller moderna dentro do JD Edwards. Quando você remove a execução de SQL do Form Design Aid (FDA) e a encapsula dentro de uma NER, você ganha um único ponto de manutenção. Se uma tabela customizada como a F554101 exigir um novo índice ou validação, você modifica a NER central uma vez, em vez de pesquisar em dezenas de formulários de entrada de APPL.
Para processamento em lote, um UBE de alto volume como um R42565 customizado que processa dezenas de milhares de registros se beneficia significativamente deste design. Em vez de repetir blocos complexos de Fetch Single no evento Do Section da seção de detalhes principal, o UBE chama a NER customizada com um Action Code de 'G' para buscar sobreposições de preço. O UBE trata a estrutura de dados retornada de forma limpa, avaliando a flag de sucesso antes de formatar a linha de saída.
Quando a operação de tabela envolve gravações não bloqueantes, como a atualização de uma tabela de log de auditoria customizada como a F559801, os desenvolvedores podem marcar com segurança a flag de execução Assíncrona nas propriedades de chamada da BSFN. Isso permite que a thread interativa primária continue o processamento sem esperar pelo reconhecimento da gravação no banco de dados. Executar a NER de forma assíncrona evita lentidão na interface do usuário durante horas de pico transacional, mantendo a interação com o banco de dados padronizada.
Ganhos de Performance e Manutenção em Campo
Em uma refatoração recente de um sistema de alocação de inventário customizado para um grande distribuidor de metais, substituímos instruções de Table I/O dispersas das tabelas F41021 e F4111 em várias aplicações de entrada diferentes por uma única NER consolidada. Essa mudança arquitetônica reduziu a contagem de linhas de event rules customizadas em quase metade nos objetos afetados. Ao remover blocos redundantes de select, fetch e update de eventos de formulário individuais, eliminamos o código espaguete que anteriormente obscurecia a lógica de negócio real.
Consolidar o Table I/O em uma NER compilada reduz diretamente o tamanho das especificações geradas (specsEspecificações; os metadados técnicos que definem o comportamento e a aparência de todos os objetos no JD Edwards.) para as aplicações e UBEs chamadores. Quando uma APPL ou UBE tem menos instruções de Table I/O de ER incorporadas, o mecanismo de tempo de execução gasta menos tempo analisando e carregando specs na memória durante a execução. Isso resulta em melhorias mensuráveis nos tempos de lançamento de aplicações e fases de inicialização de lotes, especialmente em conexões WANWide Area Network; uma rede de computadores que abrange uma grande área geográfica, como entre diferentes cidades ou países. de alta latência ou em ambientes densos de servidores HTML.
Os administradores de banco de dados se beneficiam imediatamente deste design porque ele padroniza os padrões de acesso às tabelas. Em vez de lidar com dezenas de consultas SQL ad-hoc ligeiramente diferentes geradas por várias APPLs, o mecanismo de banco de dados processa planos de execução SQL altamente previsíveis e reutilizáveis gerados através de um único objeto centralizado. Essa consistência permite que o otimizador de banco de dados armazene planos de execução em cache de forma mais eficaz, reduzindo a sobrecarga de CPU no servidor de banco de dados durante volumes de pico de transação.
Do ponto de vista da manutenção, a solução de problemas de banco de dados ou corrupção de dados não é mais uma caçada de vários dias através de event rules aninhadas. Os desenvolvedores podem abrir o JDEDebugger, definir um único breakpoint dentro da NER de Table IO designada e capturar cada tentativa de leitura ou gravação direcionada à tabela de destino. Essa capacidade de isolamento reduz o tempo médio de resolução de bugs de produção de horas de rastreamento de log para alguns minutos de depuração ativa.
Para organizações que estão estabilizando um ambiente JD Edwards 9.2, consolidar a lógica de banco de dados redundante em uma única Named Event Rule representa um método altamente eficaz para reduzir a pegada de código customizado em um quinto ou mais, simplificar caminhos de upgrade futuros e garantir a estabilidade do sistema a longo prazo.
