

Da lista bruta à estimativa: como tornar um upgrade JD Edwards defensável
Um upgrade JD Edwards não deveria começar por uma estimativa. Deveria começar por uma pergunta muito mais desconfortável: qual é realmente o escopo a ser estimado? Em teoria, a resposta parece simples. Extraem-se os objetos custom, comparam-se com o standard, verifica-se o que foi modificado e calcula-se o trabalho necessário para levá-los da release de origem para a release de destino. Na prática, essa sequência linear raramente existe. Ambientes reais contêm anos de intervenções, cópias de objetos standard, relatórios que nunca mais foram executados, objetos técnicos, versões modificadas, objetos criados para emergências há muito esquecidas, componentes de terceiros, customizações ainda críticas e customizações que ninguém mais usa. Por isso, a estimativa não pode ser o primeiro passo: deve ser a consequência de um processo de qualificação.
O ponto central é transformar uma lista brutaLista inicial, ampla e deliberadamente prudente, de objetos potencialmente relevantes para o upgrade. em uma Suggested Object ListLista fundamentada dos objetos que, após filtros e verificações, merecem permanecer no escopo de análise ou estimativa.. Essa transformação não é um exercício de redução numérica. Não se parte de milhares de objetos com o objetivo de chegar a algumas centenas porque “menos é melhor”. Parte-se de uma fotografia ampla porque, em um assessment sério, perder um objeto importante é mais perigoso do que analisar um objeto a mais. A triagem serve, portanto, para qualificar o escopo: cada objeto deve ser excluído, mantido, classificado ou reincluído por uma razão técnica documentável.
Essa distinção muda completamente a forma de interpretar o processo. Uma lista inicial ainda não é uma lista de trabalho. É uma coleção de candidatos. Alguns candidatos serão confirmados, outros serão reclassificados, outros ainda poderão ser retirados do escopo operacional do upgrade. Mas nenhuma decisão deveria ser invisível. Um objeto não desaparece porque alguém quer reduzir o número final. Ele sai do escopo apenas se houver um critério verificável: por exemplo, porque é standard, porque pertence a uma categoria que não exige retrofit aplicativo, porque não é mais usado, porque é tratado separadamente ou porque o cliente decide conscientemente não incluí-lo.
Por que a lista inicial deve ser ampla
O primeiro erro a evitar é procurar uma lista “limpa” cedo demais. Em um ambiente JD Edwards maduro, o que parece simples pode esconder dependências complexas. Um relatório pode parecer custom, mas ser quase idêntico ao standard. Uma cópia pode parecer inofensiva, mas derivar de um objeto standard que a Oracle modificou na release de destino. Uma versão batch pode parecer secundária, mas ser usada no fechamento mensal. Um objeto técnico pode parecer fora do escopo, mas ser necessário para fazer uma cadeia de processos funcionar. Por isso, a fase inicial deve aceitar certa redundância informativa: é melhor começar de forma ampla e depois qualificar, do que começar estreito e descobrir tarde demais que elementos relevantes foram perdidos.
Os extratosArquivos produzidos a partir do ambiente do cliente que descrevem objetos, versões, metadados, uso, diferenças e outros elementos úteis ao assessment. recebidos do cliente servem justamente para construir essa fotografia inicial. Eles não são um simples anexo administrativo: são a matéria-prima de todo o processo. Devem ser recebidos, preservados, organizados e transformados em dados trabalháveis sem perder o vínculo com a fonte original. Essa separação entre dados recebidos, dados processados e resultados finais é fundamental para manter a rastreabilidade. Se um número for contestado, se um objeto for reincluído, se uma estimativa for revisada, deve ser possível rastrear a razão e a fonte.
A lista bruta, portanto, não é um erro a corrigir. É uma fase necessária. Ela contém ruído, mas também contém sinais importantes. O trabalho do assessment consiste em distinguir os dois. O valor não está em produzir imediatamente uma lista aparentemente elegante, mas em construir um caminho que deixe claro por que alguns elementos são mantidos e outros não.
A triagem não é um corte: é uma classificação
A palavra “triagem” pode ser enganosa. Pode dar a ideia de um corte mecânico, quase contábil: pega-se uma lista, eliminam-se linhas, obtém-se um número menor. Em um upgrade JD Edwards feito seriamente, a triagem é, na verdade, uma classificação progressiva. Cada objeto é lido dentro de uma categoria técnica. É um objeto standard? É um custom puro? É uma modificação direta de um standard? É uma cópia de um standard? É uma versão? É um relatório batch? É um objeto que não é mais executado? É um componente técnico que não deve ser estimado como desenvolvimento aplicativo? É uma anomalia a levar à atenção do cliente?
Essa classificação é o que torna o assessment defensável. Não basta dizer que um objeto foi excluído. É preciso poder dizer por quê. Não basta dizer que um objeto foi mantido. É preciso poder explicar que risco ele representa. Não basta dizer que uma cópia foi identificada. É preciso entender de qual standard ela deriva, se esse standard mudou, quanto a cópia se afastou da referência e que trabalho será necessário para levá-la à nova release.
Nesse sentido, a triagem se parece mais com uma revisão editorial do que com uma limpeza automática. Uma revisão editorial não apaga frases aleatoriamente: distingue o que é necessário, o que é redundante, o que é ambíguo e o que exige reescrita. Da mesma forma, a triagem técnica distingue os objetos que exigem retrofit, os que exigem verificação, os que exigem decisão, os que não devem pesar na estimativa e os que não podem ser ignorados.
Objetos standard, modificações e custom puro
Uma das primeiras distinções diz respeito à natureza do objeto. Um objeto standard puro não deve ser tratado como objeto custom. Se não contém uma personalização do cliente, não deveria pesar como atividade de retrofit custom. Isso não significa que o standard seja irrelevante: o standard é a referência contra a qual se mede o impacto do upgrade. Mas a estimativa do trabalho custom deve se concentrar no que o cliente efetivamente modificou, copiou, estendeu ou criou.
Diferente é o caso das modificações diretas em objetos standard. Aqui o problema é imediato: se o standard Oracle muda na release de destino, a personalização do cliente deve ser reinterpretada no novo contexto. Não se trata apenas de mover código ou configurações de um ambiente para outro. Trata-se de entender se a modificação do cliente ainda é válida, se entra em conflito com o novo standard, se pode ser eliminada porque foi absorvida pela release de destino ou se precisa ser reescrita para conviver com o novo comportamento.
O custom puroObjeto criado pelo cliente ou para o cliente, não necessariamente derivado de um objeto standard Oracle. apresenta outro tipo de problema. Se for realmente independente do standard, pode não exigir uma comparação direta com um objeto Oracle de origem. Mas isso não o torna automaticamente simples. Ele pode depender de tabelas, funções, business views, data structures, processing options ou lógicas que mudam entre releases. Pode compilar sem erros, mas produzir resultados diferentes. Pode ser tecnicamente válido, mas funcionalmente obsoleto. Por isso, o custom puro também deve ser qualificado, não apenas contado.
O caso mais delicado: as cópias dos standards
As cópias de objetos standard estão frequentemente entre os objetos mais críticos em um upgrade JD Edwards. Uma cópia não é um duplicado e não é um objeto a descartar: é um objeto custom que preserva uma relação técnica com um objeto standard Oracle, o chamado based-onO objeto standard Oracle do qual uma cópia custom deriva ou contra o qual deve ser comparada.. Essa relação é o coração do problema. Se uma cópia deriva de um standard, seu destino não depende apenas do que o cliente fez na cópia, mas também do que a Oracle fez no standard na nova release.
Quando a Oracle modifica o objeto standard na release de destino, a cópia não pode ser tratada como se vivesse isolada. Se a cópia do cliente é substancialmente idêntica ao standard de origem, o trabalho pode ser relativamente simples: pode ser necessário recriá-la ou realinhá-la a partir do novo standard. Mas mesmo nesse caso ela não é descartada. Ela é classificada como uma cópia de baixa divergência, ou seja, como um objeto que pode ser simples de tratar, mas que ainda precisa seguir o caminho correto.
O verdadeiro problema surge quando ambas as linhas evolutivas se moveram. De um lado, a Oracle modificou o based-on na release de destino; de outro, o cliente modificou a cópia no seu próprio ambiente. Nesse ponto, o upgrade se torna um exercício de reconciliação entre duas histórias diferentes do mesmo objeto. É preciso entender quais mudanças da Oracle são importantes, quais personalizações do cliente devem ser preservadas, quais partes estão obsoletas, quais entram em conflito e qual é a forma mais segura de reconstruir o objeto final. É aqui que uma cópia pode se tornar muito mais difícil do que um custom puro.
Essa é a razão pela qual as cópias dos standards nunca deveriam ser tratadas como duplicados. Uma cópia não é uma linha a eliminar para aliviar a lista. É uma categoria de análise. Em alguns casos será simples, em outros será complexa, em outros ainda exigirá uma comparação muito detalhada. Mas o critério nunca é “é uma cópia, então se descarta”. O critério correto é: é uma cópia, então é preciso identificar o based-on, medir a divergência, verificar a mudança do standard e estimar o trabalho de recomposição.
Esse tema merece um aprofundamento próprio, porque envolve técnicas de comparação, similaridade, estrutura, nomenclatura e conhecimento funcional. Para uma explicação específica sobre o reconhecimento de cópias standard no JD Edwards, pode-se consultar o artigo Copies of JD Edwards Standards: how I identify them.
Last Run Date: quando o uso real entra no assessment
Outro critério crucial é a Last Run DateData da última execução conhecida de um relatório ou versão batch. É usada como indicador de uso real, não como verdade absoluta., frequentemente abreviada como LRD. Esse dado introduz uma dimensão que a comparação técnica sozinha não consegue fornecer: o uso real. Um objeto pode ser custom, tecnicamente válido e historicamente importante, mas se não é executado há muito tempo, é razoável perguntar se ainda deve entrar no escopo operacional do upgrade.
No caso de relatórios batch e versões, a Last Run Date é um indicador particularmente útil. Em termos JD Edwards, o dado de última execução da versão batch normalmente está associado à Versions List, isto é, à tabela F983051Tabela de versões do JD Edwards. O campo VRVED é comumente usado como Date - Last Executed para versões batch., em particular ao campo VRVEDCampo indicado como Date - Last Executed; representa a data de última execução da versão.. O histórico dos jobs submetidos também pode oferecer informações úteis, por exemplo por meio da lógica dos submitted jobs e da tabela F986110Job Control Status Master: tabela que mantém registros sobre o status dos jobs submetidos às filas.. No entanto, esses dados devem ser lidos com prudência: o histórico pode ser afetado por limpezas, retenção, configurações e comportamentos diferentes entre ambientes.
No processo de assessment, um limite prático pode ser o de 18 meses. Se um relatório não consta como executado há mais de 18 meses, pode se tornar candidato à exclusão do escopo operacional do upgrade. A palavra importante é “candidato”. Isso não significa que o relatório seja automaticamente apagado, ignorado ou declarado inútil. Significa que o dado de uso abre uma pergunta: esse relatório ainda é necessário? Foi substituído? É executado manualmente de forma rara, mas crítica? É usado apenas no fechamento anual? É lançado por outro processo que não atualiza corretamente a data esperada? É um objeto de emergência que o negócio quer manter?
Essa cautela é essencial. Um critério baseado em LRD não deve virar uma guilhotina. Deve se tornar uma conversa técnica e funcional. Se um relatório não roda há dois anos e ninguém sabe mais para que serve, é razoável não fazê-lo pesar como objeto plenamente operacional. Se, ao contrário, ele não roda há dois anos porque é usado apenas em cenários excepcionais, mas regulatoriamente importantes, a discussão muda. A Last Run Date não toma a decisão no lugar do analista: ela torna visível uma pergunta que, de outro modo, permaneceria escondida.
O limite de 18 meses não é uma verdade matemática
O limite de 18 meses é útil porque obriga a distinguir entre objetos ainda vivos e objetos provavelmente dormentes. Mas não deve ser apresentado como uma verdade matemática. Em alguns contextos, um relatório não executado há 18 meses pode ser irrelevante. Em outros, pode ser raro, mas indispensável. Um processo anual, uma obrigação fiscal, uma verificação de auditoria ou uma função de emergência podem ter baixa frequência e alta importância. Por isso, o critério temporal deve ser combinado com o conhecimento do negócio.
A forma correta de usar a LRD é inseri-la em uma matriz de decisão. Um relatório custom recente entra fortemente no escopo. Um relatório antigo, não executado e não reconhecido pelo negócio pode ser candidato à exclusão. Um relatório antigo, mas confirmado pelo cliente, permanece. Um relatório sem Last Run Date confiável exige verificação adicional. Em todos os casos, a decisão deve permanecer rastreável.
Esse também é um ponto importante na relação com o cliente. Dizer “não estimamos este relatório porque ele não roda há 18 meses” é fraco demais. Dizer “este relatório é candidato à exclusão porque a Last Run Date indica ausência de uso recente; pedimos confirmação funcional antes de removê-lo do escopo operacional” é muito mais sólido. No primeiro caso, impõe-se um corte. No segundo, constrói-se uma decisão compartilhada.
Objetos técnicos, administrativos e anomalias
Nem todos os objetos que aparecem na lista inicial devem ser tratados como desenvolvimento aplicativo a ser retrofittado. Alguns pertencem a categorias técnicas ou administrativas que exigem tratamento diferente. Pode haver elementos ligados a configurações, versões, metadados, estruturas de suporte ou componentes que não representam uma modificação aplicativa no sentido tradicional. Incluí-los sem distinção na estimativa corre o risco de inflar o escopo e confundir o trabalho realmente necessário.
Isso não significa que esses objetos sejam irrelevantes. Significa que devem ser separados. Um objeto técnico pode não exigir retrofit, mas pode exigir controle. Uma versão pode não ser um programa, mas pode conter processing options, data selection ou configurações operacionais relevantes. Uma anomalia pode não se transformar imediatamente em horas de desenvolvimento, mas pode indicar um risco a esclarecer antes de prosseguir. A qualidade do assessment está justamente na capacidade de distinguir trabalho de desenvolvimento de trabalho de verificação, configuração, decisão ou limpeza.
As anomalias merecem uma discussão à parte. Em um processo maduro, não devem ser escondidas. Um objeto sem correspondência clara, uma cópia com based-on incerto, uma versão associada a um relatório pouco claro, um registro incoerente, um nome ambíguo ou uma informação ausente não deveriam ser forçados dentro de uma categoria apenas para fechar a lista. Devem ser evidenciados. Às vezes a anomalia se resolve com uma verificação técnica. Às vezes exige envolvimento do cliente. Às vezes vira uma nota na estimativa. Em todo caso, é melhor uma lista com warnings explícitos do que uma lista aparentemente limpa construída sobre decisões não documentadas.
Reinclusões manuais: quando o julgamento técnico prevalece sobre o filtro
Um bom processo de triagem não deve ser cego. Filtros são necessários, mas não devem substituir o julgamento técnico. Existem casos em que um objeto pode parecer excluível segundo um critério automático, mas deve ser reincluído porque o analista reconhece um risco, uma dependência ou uma particularidade. Isso é especialmente verdadeiro em sistemas JD Edwards com muitos anos de história, onde convenções locais, nomenclaturas não standard e soluções de projeto podem tornar imperfeita qualquer regra automática.
A reinclusão manual não é uma falha do método. É um componente necessário. Um assessment totalmente automático pode ser rápido, mas corre o risco de ser frágil. Um assessment técnico sério combina regras, dados e julgamento. O ponto não é eliminar a intervenção humana; é torná-la rastreável. Se um objeto é reincluído, a razão deve estar clara. Se é excluído apesar de um warning, deve estar claro quem tomou a decisão e com base em quê.
Esse equilíbrio entre automação e responsabilidade é uma das diferenças entre uma lista produzida por uma ferramenta e um verdadeiro processo de upgrade assessment. A ferramenta pode acelerar, comparar, destacar, agregar, medir. Mas o valor final nasce quando os resultados são interpretados dentro do contexto do cliente e da release de destino.
O que mostram os dados históricos
Para dar concretude ao método, é útil observar uma amostra histórica anônima composta por 54 runs de assessment. A amostra contém 358,046 objetos na lista bruta inicial. Após a fase de qualificação, a Suggested Object ListLista dos objetos que permanecem no escopo técnico sugerido após exclusões, verificações e classificações. contém 145,773 objetos, enquanto 212,269 objetos são excluídos ou retirados do escopo operacional do upgrade.
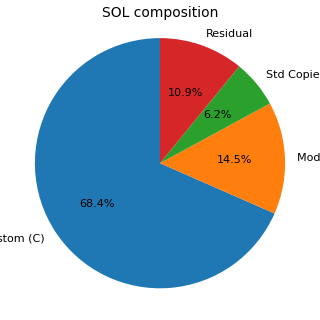
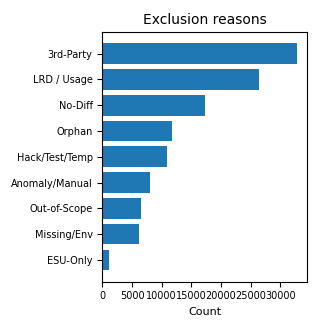
No primeiro gráfico, Residual indica a parte da Suggested Object List não coberta pelas três categorias C, M e Y mostradas no resumo agregado. No segundo gráfico, os motivos de exclusão são apresentados em gráfico de barras porque as categorias não são exclusivas e, portanto, não podem ser representadas corretamente como fatias de uma única pizza.
| Indicador | Valor agregado | Leitura do dado |
|---|---|---|
| Runs analisados | 54 | Assessments com detalhe disponível e vinculável ao resumo. |
| Objetos na lista bruta | 358,046 | Escopo inicial deliberadamente amplo. |
| Objetos na Suggested Object List | 145,773 (40.7%) | Objetos mantidos no escopo técnico sugerido. |
| Objetos excluídos | 212,269 (59.3%) | Objetos removidos do escopo operacional após aplicação dos critérios de triagem. |
| Custom puro na SOL | 99,733 | Objetos classificados como custom. |
| Standards modificados na SOL | 21,145 | Objetos standard modificados pelo cliente e mantidos no escopo. |
| Cópias de standards na SOL | 8,989 (6.2% da SOL) | Objetos do tipo cópia standard, a serem tratados como categoria crítica e não como duplicados. |
| Objetos excluídos antes da classificação | 212,188 | Objetos que saíram do escopo antes que fosse necessário estabelecer o tipo de modificação. |
| Standards modificados excluídos como no-diff | 17,036 | Objetos inicialmente classificados como modificados, mas depois encontrados alinhados ao standard. |
| UBE/UBEVER na lista bruta | 69,567 | Relatórios e versões batch presentes no escopo inicial. |
| UBE/UBEVER na SOL | 30,337 | Relatórios e versões batch mantidos no escopo sugerido. |
| UBE/UBEVER excluídos | 39,229 (56.4% dos UBE/UBEVER brutos) | Relatórios e versões batch excluídos ou candidatos à exclusão após qualificação. |
| Exclusões LRD / uso não recente | 26,328 | Objetos excluídos com motivação ligada à Last Run Date ou à falta de uso recente. |
| Exclusões no-diff | 17,297 | Objetos excluídos por não apresentarem diferenças relevantes em relação ao standard. |
| Exclusões de terceiros | 32,896 | Objetos atribuíveis a componentes fora do escopo custom do cliente. |
| Hack, teste ou temporários | 10,852 | Objetos excluídos por estarem ligados a testes, workarounds temporários ou elementos não estruturais. |
| Órfãos | 11,676 | Objetos identificados como não mais conectados a um uso operacional claro. |
| ESU-only | 1,162 | Objetos excluídos por serem atribuíveis a lógicas de atualização standard já cobertas pelo caminho de release. |
| Missing / environment | 6,098 | Objetos cuja exclusão depende de condições do ambiente ou de dados ausentes. |
| Fora do escopo do projeto | 6,482 | Objetos não pertinentes ao escopo operacional do assessment. |
| Anomalias / revisão manual | 8,079 | Casos que exigem atenção, confirmação ou julgamento técnico. |
| Excluídos sem razão explícita | 89,300 | Controle de qualidade do dado: linhas excluídas sem razão legível no campo de comentários. |
Nota metodológica. As categorias de exclusão são flags não mutuamente exclusivos: um mesmo objeto pode ter múltiplas razões documentadas, por exemplo ser um objeto de teste, de terceiros e com indicação LRD. Por isso, as linhas relativas aos motivos de exclusão não devem ser somadas entre si. O dado agregado mostra o peso dos critérios, não uma repartição exclusiva.
Esses números tornam visível o valor da triagem. Na amostra histórica, cerca de 59.3% dos objetos iniciais não chega à Suggested Object List. O dado não deve ser lido como uma simples “redução”: deve ser lido como resultado de uma classificação técnica. A lista bruta captura tudo o que poderia ser relevante; a lista sugerida preserva o que merece ser discutido, analisado ou estimado. Entre esses objetos permanecem quase 8,989 cópias de standards, confirmando um ponto essencial: cópias não são tratadas como descarte, mas como uma categoria crítica do retrofit.
O dado sobre UBEs e versões batch é igualmente significativo. De 69,567 relatórios ou versões presentes no escopo inicial, 30,337 permanecem na lista sugerida e 39,229 saem do escopo operacional. Uma parte relevante dessas exclusões está ligada à LRD ou a critérios de uso não recente. Aqui também o número não substitui o julgamento: um relatório raro pode ser crítico, mas um relatório não executado há anos deve pelo menos ser questionado antes de pesar na estimativa.
Por fim, o dado sobre objetos no-diff mostra por que não basta confiar na classificação inicial. Na amostra existem 17,036 objetos inicialmente atribuíveis à categoria de standards modificados, mas depois excluídos porque não mostram diferenças relevantes. Esse é um dos passos que impedem a estimativa de inflar artificialmente: um objeto que parece modificado não deve pesar como retrofit se a comparação demonstra que, na realidade, está alinhado ao standard.
Da Suggested Object List à estimativa
Só depois da fase de qualificação faz sentido estimar. A Suggested Object List não é o ponto final: é o ponto em que a estimativa pode começar de forma séria. Nesse momento, os objetos já não são simples nomes. São elementos classificados: custom puro, modificação de standard, cópia de standard, relatório batch com uso recente, relatório batch candidato à exclusão, versão com override, objeto técnico, anomalia, componente a verificar, elemento a discutir com o cliente.
A estimativa deve partir dessa classificação. Um custom puro, uma modificação direta de standard e uma cópia de standard não têm o mesmo perfil de risco. Uma cópia quase idêntica ao based-on e uma cópia fortemente divergente não exigem o mesmo esforço. Um relatório usado ontem e um relatório não executado há anos não têm o mesmo peso operacional. Um objeto com anomalias não pode ser estimado como se estivesse completamente claro. A estimativa não deve ser uma média genérica aplicada a uma lista: deve ser uma avaliação derivada da natureza do objeto.
Nessa segunda fase, cada objeto é traduzido em trabalho potencial. A pergunta deixa de ser apenas “o que é?”, e passa a ser “o que precisa ser feito para levá-lo corretamente à release de destino?”. A resposta pode incluir recompilação, comparação, retrofit, reconstrução a partir do novo standard, verificação funcional, testes, ajuste de processing options, controle de data selection, análise de dependências ou simples confirmação de exclusão. A estimativa torna-se, assim, o resultado de uma cadeia: dados iniciais, filtros, classificação, decisões, esforço.
Por que uma estimativa sem triagem é perigosa
Estimar diretamente a lista bruta é perigoso por duas razões opostas. A primeira é a superestimativa. Se objetos standard, objetos não usados, elementos técnicos não aplicativos ou relatórios dormentes permanecem na lista, o cliente recebe uma estimativa carregada com trabalho que talvez não seja necessário. Isso pode tornar o projeto mais caro, mais difícil de aprovar e menos transparente.
A segunda razão é a subestimativa. Se as cópias dos standards são lidas como simples duplicados, se modificações diretas no standard são tratadas como custom comum, se anomalias são ignoradas, a estimativa pode parecer mais leve, mas tornar-se frágil. O risco aparece mais tarde, quando o projeto já começou e os objetos mais complexos passam a exigir tempo não previsto.
A triagem serve para evitar ambos os erros. Não é um mecanismo para reduzir a estimativa. É um mecanismo para torná-la proporcional. Retira peso onde o trabalho não existe, mas adiciona atenção onde o risco é real. Esse é o ponto mais importante a comunicar ao cliente: a redução do escopo não é um atalho, é uma forma de precisão.
A rastreabilidade como valor do método
Um assessment de upgrade não produz apenas números. Produz decisões. Cada exclusão, inclusão, reinclusão ou classificação é uma decisão. Se essas decisões não forem rastreadas, a estimativa final se torna difícil de defender. Se forem documentadas, o cliente pode entender não apenas quanto trabalho está previsto, mas também por quê.
A rastreabilidade também é importante para a equipe de projeto. Quando o upgrade entra na fase executiva, as pessoas que trabalham nos objetos precisam saber de onde veio a classificação. Precisam entender se um objeto foi considerado cópia, se o based-on é certo ou provável, se a Last Run Date influenciou a decisão, se um relatório foi excluído por confirmação do cliente, se um warning permaneceu aberto. Sem essa memória, o assessment corre o risco de virar um documento estático. Com essa memória, torna-se uma ferramenta operacional.
A rastreabilidade também serve para gerenciar revisões. Uma estimativa pode mudar. Um cliente pode reincluir um relatório. Um objeto inicialmente considerado simples pode se revelar complexo. Uma cópia pode mostrar divergência maior do que o previsto. Se o processo é rastreado, a revisão é compreensível. Se não é, cada mudança parece arbitrária.
O papel do cliente na validação do escopo
O cliente não deveria receber a Suggested Object List como uma sentença. Deveria recebê-la como um escopo técnico a validar. A equipe técnica pode dizer que um relatório não consta como executado há mais de 18 meses, mas só o cliente pode confirmar se esse relatório está realmente abandonado. A equipe técnica pode identificar uma cópia e medir sua divergência, mas muitas vezes é necessário conhecimento funcional para entender quais modificações ainda são relevantes. A equipe técnica pode sinalizar uma anomalia, mas o cliente pode saber que essa anomalia corresponde a um procedimento antigo, a um workaround ou a uma customização crítica.
A qualidade do upgrade depende, portanto, também da forma como o escopo é discutido. Um assessment não deveria produzir uma lista fechada em isolamento. Deveria produzir uma lista motivada, acompanhada de critérios, notas, warnings e perguntas. Dessa forma, o cliente não é obrigado a confiar em um número: pode ver o caminho que produziu esse número.
Isso é particularmente importante em projetos com forte pressão econômica. Uma lista grande demais assusta. Uma lista pequena demais cria risco. Uma lista defensável permite uma discussão racional: quais objetos estão certamente no escopo, quais são candidatos à exclusão, quais exigem confirmação, quais são tecnicamente críticos, quais são funcionalmente sensíveis.
Do dado técnico à decisão de projeto
O valor final do procedimento não é apenas técnico. É decisório. Um upgrade JD Edwards é um projeto em que o risco frequentemente nasce da incerteza: não saber quantos objetos estão realmente envolvidos, não saber quais cópias são críticas, não saber quais relatórios ainda são usados, não saber se uma estimativa inclui objetos inúteis ou exclui objetos importantes. O procedimento reduz essa incerteza transformando informações dispersas em decisões visíveis.
Isso não significa eliminar toda margem de dúvida. Em um sistema complexo, a dúvida não desaparece. Ela é gerenciada. Alguns objetos permanecerão com notas. Algumas decisões exigirão confirmação. Algumas estimativas terão margens. Algumas cópias exigirão análises mais profundas. Mas uma margem declarada é muito diferente de uma margem escondida. A primeira pode ser discutida. A segunda explode durante o projeto.
Nesse sentido, o procedimento de upgrade assessment não é simplesmente uma forma de produzir uma estimativa. É uma forma de construir confiança. Confiança de que o escopo não é arbitrário. Confiança de que objetos críticos não foram simplificados. Confiança de que relatórios não usados foram tratados com critério. Confiança de que cópias dos standards foram compreendidas pelo que são: frequentemente o ponto mais delicado do retrofit.
Conclusão: o upgrade como redução da incerteza
Um upgrade JD Edwards não é apenas uma passagem técnica de uma release para outra. É um exercício de redução da incerteza. No início existe uma massa de objetos potencialmente relevantes. No final deve haver um escopo explicável, uma lista sugerida, uma estimativa proporcional e uma série de decisões rastreáveis. O trabalho mais importante acontece exatamente no meio, na fase em que a lista bruta é transformada em conhecimento.
A triagem é o coração desse processo, mas apenas se for entendida corretamente. Ela não serve para eliminar linhas. Serve para distinguir. Objetos standard não devem ser confundidos com custom. Relatórios não usados há mais de 18 meses podem ser candidatos à exclusão, mas não apagados sem julgamento. Anomalias devem ser evidenciadas, não escondidas. Reinclusões manuais fazem parte do método, não são exceções embaraçosas. E cópias dos standards não são duplicados: são frequentemente os objetos mais delicados, porque obrigam a comparar a evolução do cliente com a evolução do standard Oracle.
Só quando esse trabalho foi feito a estimativa se torna crível. Não porque seja perfeita, mas porque é explicável. E em um upgrade complexo, uma estimativa explicável vale muito mais do que uma estimativa aparentemente precisa, mas sem memória técnica.
