
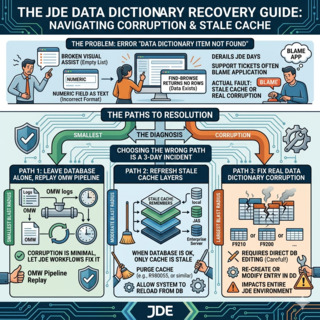
"Data Dictionary Item Not Found" é o erro que mais rapidamente atrapalha um dia de JD Edwards. Os usuários veem um Visual Assist quebrado, um campo numérico sendo renderizado como texto, ou um Find-Browse que não retorna nada onde ontem retornava linhas — e o primeiro reflexo em metade dos tickets de suporte que já vi é culpar a aplicação, quando a falha real quase sempre está uma camada abaixo: uma entrada de Data DictionaryA camada de metadados do JDE que define cada data item (alias, tamanho, casas decimais, glossário, regras de edição). Ela governa como cada formulário, BSFN e UBE interpreta as colunas subjacentes. que não corresponde mais ao que uma das quatro camadas de cache acima dela ainda lembra.
Este guia é o procedimento que uso para corrigir erros de Data Dictionary no JD Edwards quando a corrupção é real, quando é apenas cache desatualizado, e quando o caminho mais seguro é deixar o banco de dados em paz e permitir que o pipeline OMWObject Management Workbench: o console JDE que controla check-out, check-in, promoção e histórico de auditoria de cada alteração de objeto, incluindo itens do Data Dictionary. reproduza a alteração. Os três caminhos têm raios de impacto muito diferentes, e a escolha errada transforma uma correção de 10 minutos em um incidente de 3 dias.
Por que a hierarquia de cache quase sempre é a verdadeira culpada
Antes de tocar uma única linha em F9200 ou F9210, internalize isto: o JDE procura um data item por meio de quatro a cinco camadas de cache em sequência, e qualquer uma delas pode estar segurando uma cópia desatualizada da definição enquanto todas as outras camadas estão corretas. O erro que o usuário vê é idêntico, esteja a corrupção no banco de dados ou apenas em um cache que precisa ser limpo.

O fat client, onde ainda existe, armazena entradas DD localmente dentro dos arquivos de spec da estação de trabalho. O HTML ServerO servidor web baseado em Java que entrega a interface web do JDE EnterpriseOne. Ele mantém caches em memória por usuário e por ambiente de metadados acessados com frequência, incluindo itens do Data Dictionary. mantém um cache JVM em memória, atualizado de forma preguiçosa. O Enterprise ServerO backend baseado em C que executa Call Object kernels, UBE kernels e outros processos de servidor. Seu cache DD fica na memória de processo de cada kernel e é independente do cache do HTML Server. mantém seu próprio cache dentro de cada Call Object kernel — e sim, cada kernel tem sua própria cópia, por isso dois usuários executando o mesmo formulário podem ver comportamentos diferentes. Abaixo disso ficam as tabelas de spec por path code, e abaixo delas as tabelas master centrais F9200 (Data Item Master), F9202 (alpha description), F9203 (traduções) e F9210 (Data Item Specifications).
A regra prática: em cerca de 70–80% dos tickets de "corrupção de data dictionary" em que trabalhei, nada estava corrompido. Uma alteração DD havia sido promovida, mas uma das camadas de cache acima não tinha sido atualizada, e a aplicação estava simplesmente lendo uma definição antiga. Limpar os caches na ordem correta resolve o problema em menos de 10 minutos e não toca o banco de dados.
Os 20–30% restantes são corrupção real: uma linha ausente na F9210 que existe na F9200, uma tradução obsoleta na F9203 para um código de idioma que não está mais ativo, ou uma colisão de chave primária depois de uma restauração com falha. Esses casos exigem correções cirúrgicas, e é aí que as próximas seções importam.
Os três caminhos de reparo e quando escolher cada um
Depois de confirmar que o problema é reproduzível entre usuários e ambientes — ou seja, não é apenas um cache desatualizado isolado — você tem três opções. A tentação é sempre pular direto para SQL, e isso quase sempre é a decisão errada.

Cache clear pelo Server Manager é sempre a primeira coisa a tentar. Abra o Server Manager, selecione a instância HTML Server de destino, navegue até Runtime Metrics e limpe o cache do Data Dictionary. Depois faça o mesmo em cada logic kernel do Enterprise Server que atende os usuários afetados. Toda a operação leva 5–10 minutos e altera zero linhas no banco de dados. Se o sintoma desaparecer, a corrupção nunca foi real — era uma divergência de cache — e o trabalho terminou.
P92001 (Data Dictionary Design) é a aplicação JDE padrão para gerenciar itens DD. Se a limpeza de cache não ajudou, abra a P92001 no alias problemático, verifique se a definição corresponde ao que a aplicação espera e, se necessário, salve o item novamente. A P92001 grava em F9200/F9210, propaga para as tabelas de spec, e a alteração passa a fazer parte da trilha de auditoria do OMW. Esse é o único caminho de reparo que sobrevive de forma limpa a um upgrade ou retrofit de ESU, porque deixa um registro rastreável de quem alterou o quê e quando.
Direct SQL contra F9200/F9210/F9202/F9203 é o último recurso. Você usa isso apenas quando a P92001 se recusa a operar na linha — normalmente por causa de um registro órfão, uma duplicata que não deveria existir ou uma violação de chave primária. Cirurgia SQL exige backup completo das quatro tabelas antes de começar, aprovação do DBA e da equipe CNC, e um relatório de integridade executado imediatamente depois. Do ponto de vista do JDE, ela não é auditável: a alteração não deixa rastro no OMW, não tem histórico de versão, não tem botão de rollback.
As consultas de diagnóstico que mostram o que está realmente errado
Antes de decidir qual caminho seguir, execute as quatro consultas que localizam a corrupção. Elas levam segundos e economizam horas de adivinhação.
Primeiro, confirme que o data item existe na F9200 (master) e na F9210 (specifications):
SELECT FRDTAI, FRDSCR, FRSY FROM F9200 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FROMDTAI, FROOWTP, FROODA FROM F9210 WHERE FROMDTAI = 'YOUR_ALIAS';Se a F9200 retorna uma linha mas a F9210 retorna zero, você tem um órfão clássico: o master existe, as especificações não, e todo formulário que referencia o alias vai falhar. O inverso — F9210 sem F9200 — é mais raro, mas pior, porque o compilador de specs tem algo contra o qual compilar, mas a aplicação nunca consegue encontrar o master.
Segundo, verifique as alpha descriptions na F9202 e as traduções na F9203 para os idiomas usados pelo site:
SELECT FRLNGP, FRALPH FROM F9202 WHERE FRDTAI = 'YOUR_ALIAS';
SELECT FRLNGP, FRALPH FROM F9203 WHERE FRDTAI = 'YOUR_ALIAS';Uma linha ausente na F9203 para o idioma ativo de um usuário é a causa mais comum de reclamações de "label em branco" — o campo tem uma descrição em inglês, mas não em italiano, e usuários italianos veem um cabeçalho vazio. Isso quase nunca é "corrupção"; é uma tradução que nunca foi criada.
Terceiro, compare o master com as tabelas centrais de spec do path code ativo. As tabelas de spec ficam na data source específica do path code (DD910, DV920, PY920, PD920, dependendo da release e do path code) e são populadas pelo processo de package build. Se a F9210 diz decimals = 2 e a tabela de spec diz decimals = 0, a aplicação está lendo a tabela de spec — o master do banco está correto, as specs compiladas estão erradas, e você precisa de um partial package build do item DD afetado, não de uma correção no banco de dados.
Quarto, execute R9202 (Data Dictionary Repair) como select contra o alias para obter um relatório gerado pelo JDE sobre a integridade das quatro tabelas. O R9202 relata órfãos, traduções ausentes e definições inconsistentes em uma única saída, formatada do jeito que o Oracle Support espera ver caso você escale.
Ordem de cache clear: errar a sequência desperdiça a operação
Se você decidir que o problema é cache, a ordem das operações importa. Limpar o cache do Enterprise Server antes do cache do HTML Server significa que o HTML Server pode repopular o cache do Enterprise Server com seus próprios dados desatualizados na próxima requisição de usuário. A sequência correta é top-down: fat clients primeiro, se houver algum envolvido, depois HTML Server, depois kernels do Enterprise Server, e então verificar se as tabelas de spec estão atuais.
No HTML Server, o Server Manager expõe "Clear Data Dictionary Cache" em Runtime Metrics da instância JAS. Isso limpa o cache JVM em memória sem reiniciar a JVM, então usuários em sessões ativas não são interrompidos. A próxima consulta DD feita por qualquer usuário puxa uma cópia nova da camada abaixo.
No Enterprise Server, o cache vive na memória de processo de cada Call Object kernel. Limpá-lo exige reiniciar o kernel (interrompe chamadas em andamento) ou usar a interface de comandos runtime do kernel pelo Server Manager. Na prática, em um ambiente ocupado, a abordagem mais limpa é um rolling restart dos Call Object kernels — derrubar uma fração por vez, deixar o load balancer redirecionar, repetir. Toda a operação em uma configuração com 16 kernels leva cerca de 8–12 minutos e é invisível para os usuários.
As tabelas de spec (DD3xxxnn-style central spec store) são atualizadas durante package builds. Se uma alteração DD foi promovida mas nenhum package build foi executado, as tabelas de spec estão desatualizadas e nenhuma limpeza de cache ajuda — os kernels estão lendo cache correto a partir de specs incorretas. Um partial package build do item DD afetado, normalmente de 5–15 minutos dependendo do tamanho do ambiente, é a correção.
Quando SQL é inevitável, o procedimento seguro
Cirurgia SQL nas tabelas F92xx só se justifica quando a P92001 se recusa a corrigir a linha e o relatório de integridade confirma um órfão ou duplicata real. O procedimento é:
Passo um, backup completo das tabelas F9200, F9202, F9203, F9210 na data source afetada, com a data no nome do backup. Não um export lógico — uma cópia CREATE TABLE AS SELECT que permita fazer comparações linha a linha depois. Pular esse passo é como uma correção de 20 minutos vira uma situação de restore-from-tape.
Passo dois, identificar cada linha tocada pela alteração que está por vir. Se você está removendo um órfão da F9210, consulte quaisquer linhas relacionadas em F9202, F9203 e nas tabelas de spec que referenciem o mesmo alias. Uma correção limpa remove linhas relacionadas em uma única transação; deixar sobras na F9203 significa que a próxima consulta de usuário para esse alias vai encontrar um erro diferente.
Passo três, o DML dentro de uma transação com rollback explícito em caso de erro. Para uma linha F9210 órfã sem master F9200, a forma segura é:
BEGIN;
DELETE FROM F9210 WHERE FROMDTAI = 'ORPHAN_ALIAS'
AND NOT EXISTS (SELECT 1 FROM F9200 WHERE FRDTAI = 'ORPHAN_ALIAS');
-- verify row count matches expectation before commit
COMMIT;Passo quatro, execute R9202 novamente. O relatório agora deve voltar limpo para o alias afetado. Se ele ainda relatar um problema, restaure a partir do backup e escale — você encontrou algo que a exclusão simples não resolve.
Passo cinco, limpe os caches top-down (HTML, Enterprise, repetir) e reconstrua o item DD afetado nas tabelas de spec por meio de um partial package build. Sem isso, o banco de dados agora está correto, mas os kernels continuam lendo o estado antigo quebrado a partir do próprio cache.
Passo seis, documente a correção no change log CNC com o alias, o SQL executado, as contagens de linhas antes e depois, e a saída do relatório de integridade. Cirurgia SQL não é auditável pelo OMW, então a única trilha de auditoria que você tem é a que você escreve.
Os erros que transformam uma correção de 10 minutos em um incidente de 3 dias
O primeiro erro é pular a limpeza de cache e ir direto para SQL. Em cerca de 75% das vezes, o erro visível para o usuário nunca foi corrupção de banco de dados — era um kernel lendo cache desatualizado. Cirurgia SQL nessa situação não ajuda, deixa você com uma alteração não auditável para investigar depois, e arrisca introduzir corrupção real em cima de um não problema.
O segundo é limpar caches na ordem errada. Limpar primeiro o cache do Enterprise Server e depois deixar o HTML Server atualizá-lo com sua própria cópia desatualizada é uma forma clássica de passar uma hora se perguntando por que nada mudou. Top-down é a regra, sempre.
O terceiro é fazer a alteração em PD sem reproduzi-la primeiro em DV e PY. Mesmo uma correção emergencial deve ser aplicada em DV, verificada, e então promovida por PY até PD usando um projeto OMW rastreado — ou, no mínimo, o script SQL de replay deve ser reexecutado contra PY e DV depois que PD estiver estável. Deixar ambientes fora de sincronia transforma o próximo upgrade ou refresh em uma caça por discrepâncias.
O quarto é esquecer que itens DD são referenciados por aliases em código C compilado dentro de BSFNs. Se você altera o tamanho ou as casas decimais de um item DD sem recompilar cada BSFN que o utiliza, o runtime vê uma divergência entre a estrutura C e a nova definição DD. Essa divergência pode causar erros severos de runtime no Call Object kernel — não tão dramáticos quanto alguns artigos antigos gostam de afirmar, mas reais, e só corrigidos por um rebuild BSFN completo dos B-objects afetados.
O quinto é tratar corrupção na F9203 como problema de banco de dados. A maioria dos tickets de "tradução ausente" não é corrupção nenhuma — são linhas de tradução que simplesmente nunca foram criadas para o código de idioma do usuário. A correção é uma atualização na P92001 com a tradução ausente, não um reparo SQL contra a F9203.
Se esse tipo de detalhe operacional é o que você precisa para o trabalho diário de JD Edwards CNC e banco de dados, os artigos relacionados neste site cobrem padrões de projeto OMW, internos de package build e otimizações do lado SQL em tabelas JDE padrão. O portfólio de projetos mostra onde essas técnicas foram aplicadas em trabalho real de suporte à produção.
