

Alterar o índice de uma BSVWBusiness View: um objeto JD Edwards que une uma ou mais tabelas e expõe para aplicações e relatórios um conjunto fixo de colunas e um índice escolhido. parece um ajuste de cinco minutos em BVDABusiness View Design Aid: a ferramenta JD Edwards usada para definir quais colunas de tabela e qual chave a Business View expõe às aplicações., e é exatamente por isso que isso quebra mais relatórios do que qualquer outra alteração isolada no JD Edwards EnterpriseOne. Uma BSVW pode ser lida por dezenas de UBEs, APPLs e form interconnects; trocar sua chave do índice 2 para o índice 4 em OMWObject Management Workbench: o console JD Edwards que controla check-out, check-in, acompanhamento de projetos e promoção de objetos entre path codes. muda a ordem das linhas vista por cada consumer e, se mesmo um deles dependia da ordenação anterior, você acabou de introduzir um defeito de dados silencioso em produção.
Este é o procedimento que uso para uma alteração de índice de BSVW no JD Edwards com OMW e BVDA — a sequência exata, a verificação de dependências que executo antes de tocar no objeto e o caminho de rebuild que mantém a alteração limpa em DVAmbiente de desenvolvimento no JD Edwards: o path code em que os desenvolvedores fazem check-out, modificam, fazem build e executam testes unitários nos objetos antes da promoção., PYAmbiente Prototype no JD Edwards: o path code usado para testes de integração e aceite do usuário antes que os objetos sejam promovidos para produção. e PDPath code de produção no JD Edwards EnterpriseOne. O ambiente live em que usuários de negócio realizam transações; as alterações aqui são implantadas via promoção OMW a partir de PY..
Por que uma alteração de índice BSVW nunca é apenas uma alteração BSVW
Uma BSVW não armazena dados. Ela é uma definição SQLStructured Query Language: a linguagem padrão usada para consultar e manipular bancos de dados relacionais. O JDE gera SQL por trás de cada BSVW, fetch e UBE. salva sobre uma ou mais tabelas subjacentes, com um índice escolhido que determina duas coisas: o formato da cláusula WHERE e o ORDER BY padrão. Quando você altera o índice, por exemplo, da chave baseada em data para a chave baseada em número de documento, as cláusulas WHERE geradas pelo runtime mudam de formato, e a ordem em que as linhas retornam muda junto. Qualquer consumer que percorria os resultados assumindo uma ordenação por data passa a percorrê-los em ordem de número de documento, e agregações, breaks e lógicas do tipo "first record wins" mudam sem aviso.
O segundo problema é a quantidade de consumers. Uma única BSVW usada em um ambiente operacional típico pode alimentar 10–30 UBEs e 5–15 application forms. O trabalho de 30 segundos para alterar a chave no BVDA vira um trabalho de 3–4 horas para encontrar cada consumer, abrir cada um e confirmar que nenhum deles depende da ordenação anterior. Pular essa etapa é o que transforma uma otimização limpa de índice em um incidente de produção duas semanas depois, quando relatórios de agregação de fechamento mensal começam a colocar linhas no grupo errado.
O terceiro problema é que o índice precisa realmente existir na tabela subjacente. A janela "Select Key" do BVDA lista todos os índices definidos na tabela primária em nível de data dictionaryJD Edwards Data Dictionary: o repositório central das definições de data items (tabelas Fxxxx, campos de trabalho GTxxxx) que governa validação, exibição e metadados de colunas.. Se você precisa de uma chave que ainda não existe, você não está fazendo uma alteração BSVW — você está fazendo uma alteração de tabela, que é uma ordem de grandeza mais invasiva e exige o envolvimento da equipe CNCConfigurable Network Computing: a disciplina de administração do JD Edwards responsável por ambientes, path codes, server packages e implantações de banco de dados..
A verificação de dependências que executo antes de tocar no objeto
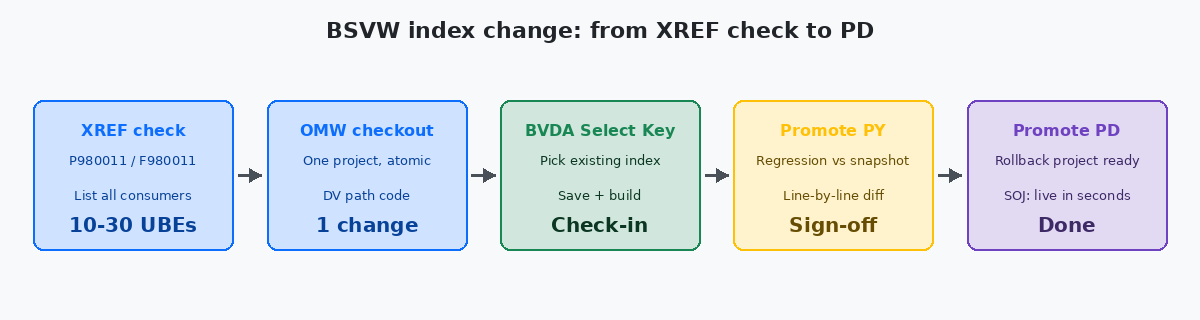
Antes de qualquer check-out, execute a pesquisa de cross-reference em P980011Aplicação Cross Application Reference Repository no JD Edwards: permite listar cada objeto (UBE, APPL, NER, BSFN) que referencia uma determinada BSVW, BSFN ou tabela. contra o nome da BSVW. O resultado é a lista completa de UBEs, APPLs e NERs que a referenciam. Para cada consumer, duas perguntas: ele itera o result set? Ele tem lógica que depende da ordem? Se a resposta for sim para ambas, esse consumer precisa estar na lista de regressão antes que a alteração seja aprovada.
Um atalho útil: leia diretamente as tabelas F9860 (Object Librarian Master) e F980011 (XREF) com um client SQL. Uma query simples — SELECT FOOBNM, FOMODNAME FROM F980011 WHERE FOPONM = 'V55XXXXA' — dá a você a mesma resposta em um segundo, em vez de navegar pelos resultados de pesquisa do OMW. O índice XREF precisa ser reconstruído periodicamente no JDE; se o último rebuild foi há meses, a lista está desatualizada e você perderá consumers adicionados recentemente. Execute primeiro o refresh do XREF.
Para cada consumer que depende da ordem, capture um snapshot "before". Execute o UBE em DV contra um dataset congelado e salve a saída. O mesmo dataset e o mesmo UBE serão executados novamente depois da alteração; o diff entre as duas saídas é o seu critério de aceite. Pular esse snapshot é como as equipes acabam discutindo com os usuários se o relatório "parece diferente" — não há medição, apenas opiniões.
A sequência OMW e BVDA, passo a passo

A mecânica real tem oito etapas, todas em DV, todas pelo OMW:
- Abra o OMW (P98220W) e localize a BSVW pelo nome (por exemplo,
V55XXXXA). - Adicione o objeto a um projeto OMW ativo. Se você não possui um projeto, crie um; não faça check-out do objeto no projeto de outra pessoa.
- Faça check-out da BSVW. O OMW avisará se ela já estiver em check-out por outro desenvolvedor — nunca quebre esse lock sem confirmar com ele.
- Abra-a no Business View Design Aid (BVDA).
- No menu: View → Select Table Columns. Confirme que a tabela primária e a lista de colunas são exatamente o que você espera. Não altere a seleção de colunas no mesmo checkout de uma alteração de índice — mantenha as alterações atômicas.
- View → Select Key. A janela lista todos os índices definidos na tabela primária. Escolha o novo key item. Anote o número da chave que você está deixando e o número para o qual está mudando; você precisará de ambos no change log do OMW.
- Salve e faça build da BSVW. Um build de BSVW é rápido (segundos), mas precisa ter sucesso localmente antes que você possa fazer check-in.
- Faça check-in. No comentário do OMW, documente a chave antiga, a nova chave e a contagem de consumers da pesquisa XREF. Essa é a trilha de auditoria que salva você quando alguém pergunta seis meses depois por que a ordenação mudou.
Se o build falhar, a causa quase sempre é que a lista de colunas ainda referencia uma coluna que não existe na tabela da nova chave — típico quando a tabela primária foi alterada em um checkout anterior e não foi commitada corretamente. A correção é reverter, não forçar.
Quando o índice de que você precisa ainda não existe
Se "Select Key" não mostrar o índice de que você precisa, você tem duas opções, e elas têm blast radii muito diferentes. Opção um: escolher o índice existente mais próximo e aceitar o trade-off. Opção dois: criar um novo índice na própria tabela. A segunda opção significa uma alteração de tabela, e uma alteração de tabela JDE é fundamentalmente diferente de uma alteração BSVW.
Uma alteração de tabela toca em TDATable Design Aid: a ferramenta JD Edwards usada para definir colunas de tabela, índices, chaves primárias e gerar o DDL que cria ou altera a tabela física do banco de dados. (Table Design Aid), gera um novo DDL e exige que o banco de dados seja fisicamente reconstruído ou alterado em cada ambiente. O novo índice precisa existir em DV, PY e PD antes que qualquer BSVW ou UBE apontando para ele funcione. A implantação pertence ao CNC, não ao desenvolvedor que precisa do índice. Planeje um ciclo de geração e implantação de server package normalmente de 1–3 dias, dependendo do calendário de releases do ambiente.
O outro risco é que adicionar um índice a uma tabela JDE padrão (por exemplo, F4211, F0911, F4101) é algo que o suporte Oracle discutirá com você se um ESU futuro tocar a mesma tabela. Você não está alterando colunas de schema — está adicionando um índice — mas o impacto no throughput de insert/update em uma tabela de alto volume é real e mensurável. Adicionar um índice à F4211 em uma operação de distribuição que processa 100.000 linhas de pedido de venda por dia é uma conversa com o CNC, não uma decisão apenas do desenvolvedor.
Se você seguir esse caminho: faça check-out da tabela no OMW, abra o TDA, adicione o índice com as colunas na ordem exata exigida pelo formato da cláusula WHERE que você deseja, salve e faça build, depois promova pelos path codes padrão. Só então a BSVW pode ser modificada para usá-lo. Dois projetos OMW separados, dois check-ins separados, duas janelas de implantação separadas.
Build e implantação da alteração em DV, PY, PD
Depois que a BSVW passa por check-in em DV, a alteração não fica visível para ninguém, exceto um desenvolvedor testando em DV. Para que ela chegue aos usuários finais, o projeto OMW precisa ser promovido: DV → PY → PD. Cada promoção precisa de um build de server package conduzido pelo CNC para o path code de destino. Uma BSVW sozinha não exige um full package build se você estiver usando specs over JavaSOJ (Specs Over Java): o modo de implantação JDE em que as especificações de objetos são servidas pelo deployment server em vez de ficarem incorporadas em um full client package, removendo a necessidade de um full package build a cada alteração. (SOJ) — esse é um dos principais benefícios do SOJ, e ele é o padrão em toda Tools Release moderna.
Em ambientes com SOJ habilitado, a spec da BSVW é lida do store central de specs assim que a promoção OMW chega. A alteração fica live imediatamente para o path code de destino. Em uma implantação não-SOJ (rara nas Tools Releases atuais, mas ainda presente em alguns sites), é necessário um full client package build e deployment antes que a alteração fique visível — uma janela de build de 30–60 minutos, dependendo do tamanho do ambiente.
O teste de regressão acontece em PY, não em DV. PY tem volumes de dados parecidos com produção e os UBEs consumers reais agendados da forma como os usuários os executam. Execute cada consumer da lista de regressão contra o snapshot congelado capturado antes da alteração. Compare linha por linha. Só depois que cada consumer corresponder às expectativas a alteração recebe sinal verde para PD.
Em PD, a janela de implantação é a que a sua política de change management determinar. A alteração BSVW em si leva segundos para entrar. O risco não é a implantação — é o primeiro UBE que roda após a implantação mostrar um resultado que ninguém esperava. Tenha pronto o projeto OMW de rollback: um segundo projeto que mantém a spec BSVW anterior, com check-in feito mas ainda não promovido, para que um engenheiro CNC possa fazer demote em minutos se um usuário reportar uma regressão na primeira hora.
Os erros que quebram esse procedimento na prática
O modo de falha mais comum é pular a etapa XREF. Um desenvolvedor altera a chave no BVDA, faz build, promove e só descobre duas semanas depois que um UBE de fechamento mensal dependia da ordenação antiga. A essa altura, um mês inteiro de relatórios foi emitido com a ordem de linhas errada, e reemiti-los vira uma conversa de finanças, não de desenvolvimento.
O segundo é juntar uma alteração de chave com uma alteração de coluna no mesmo checkout. Quando algo quebra, você não consegue saber qual alteração causou o problema. Checkouts atômicos não são burocracia — são como você mantém simples a história de rollback. Uma alteração por checkout, um projeto OMW por alteração.
O terceiro é criar o novo índice em uma tabela JDE padrão sem consultar o CNC. Uma tabela customizada com prefixo B55 é território do desenvolvedor; F4211 não é. Adicionar um índice a uma tabela padrão sem sign-off do CNC é um caminho para ter esse índice removido silenciosamente durante a próxima aplicação de ESU ou, pior, para um problema de performance em produção em um caminho de código que você não mediu.
O quarto é tratar a promoção BSVW como uma tarefa puramente de desenvolvedor. Em ambientes SOJ, o clique é pequeno, mas a alteração chega a cada UBE consumer no instante em que a spec aterrissa. Não existe soft launch. A disciplina que torna isso seguro é a lista de regressão e o snapshot do dataset congelado, não a própria UI do OMW.
Se esse tipo de detalhe procedural é o que você precisa para o trabalho operacional diário com JD Edwards, os artigos relacionados neste site cobrem análise de dados SQL em tabelas padrão e customizadas, medição de performance BSFN com logs e timings, e os padrões de projeto OMW que tornam seguros ambientes com vários desenvolvedores. O portfólio de projetos mostra onde essas técnicas foram aplicadas em trabalhos reais de upgrade e retrofit.
