Selecione seu Idioma
Meu Blog

- Detalhes
-
 By Vincenzo Caserta
By Vincenzo Caserta - Categoria: Meu blog
Dados recentes de telemetria de 2026 sugerem que o servidor web corporativo médio hoje gera mais de 1,2 terabyte de dados de log por mês, um volume que torna a inspeção manual não apenas ineficiente, mas matematicamente impossível para operadores humanos. Em uma era em que microsserviçosUm estilo arquitetural que estrutura uma aplicação como uma coleção de pequenos serviços autônomos, modelados em torno de um domínio de negócio. dominam o cenário, o humilde log do Nginx evoluiu de um simples arquivo de texto para um fluxo crítico de dados de alta velocidade. Mesmo assim, muitos administradores continuam presos a fluxos de trabalho manuais e ultrapassados, incapazes de capturar o verdadeiro pulso da infraestrutura. Entender como automatizar o gerenciamento de logs do Nginx deixou de ser luxo; é um requisito fundamental para manter a integridade e o desempenho dos sistemas em um mundo hiperconectado.
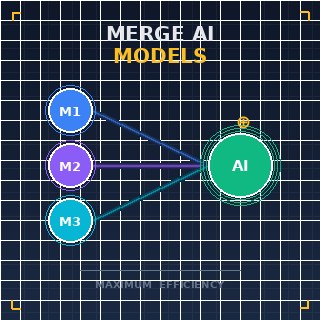
- Detalhes
- By Vincenzo Caserta
- Categoria: Meu blog
Em um laboratório de alta tecnologia em Zurique, um cientista de dados observa a tela de um terminal onde dois espíritos neurais distintos estão prestes a se tornar um só. Um modelo é mestre em biologia molecular, enquanto o outro é especialista em dinâmica de fluidos; separadamente, eles são brilhantes, mas juntos, poderiam revolucionar os sistemas de administração de medicamentos. Esta é a realidade de 2026, onde o principal desafio não é mais apenas construir sistemas maiores, mas descobrir como mesclar múltiplos Large Language Models (LLMs)Sistemas de inteligência artificial treinados em grandes volumes de texto para entender e gerar linguagem semelhante à humana. especializados em uma inteligência única e coesa. Este processo, conhecido como model merging, passou de uma curiosidade experimental para um padrão crítico de engenharia, permitindo que desenvolvedores sintetizem os pontos fortes de diversas arquiteturas sem os custos proibitivos de retreinar do zero.

- Detalhes
- By Vincenzo Caserta
- Categoria: Meu blog
Imagine um pesquisador genômico em 2026 tentando isolar uma única variante de proteína de uma biblioteca de cinquenta mil entradas usando um elemento select HTML padrão. O navegador trava, a barra de rolagem torna-se microscópica e a experiência do usuário entra em colapso sob o peso de nós DOMO Document Object Model é uma interface de programação para documentos web, representando a página para que programas possam alterar a estrutura e o conteúdo. excessivos. Para resolver isso, devemos ir além dos elementos estáticos e adotar componentes programáveis. Aprender como criar um dropdown de busca dinâmico não é mais apenas uma preferência de UI/UXDesign de Interface do Usuário e Experiência do Usuário focado nos aspectos estéticos e funcionais de como humanos interagem com o software.; é uma necessidade técnica para plataformas de gerenciamento de dados de alta performance e visualização científica.

- Detalhes
- By Vincenzo Caserta
- Categoria: Meu blog
Por que nossos modelos preditivos mais avançados, apesar de treinados no hardware mais caro disponível em 2026, ainda desmoronam diante de uma pequena mudança no contexto ambiental? Essa falha não é um bug de software, mas uma inevitabilidade matemática: a incapacidade das arquiteturas atuais de migrar com sucesso a JD (Distribuições Conjuntas) de um domínio de origem para um domínio de destino. À medida que expandimos os limites dos sistemas autônomos e da modelagem científica em tempo real, a indústria finalmente reconheceu que os dados não são um recurso estático. Para manter a precisão, devemos tratar os dados como uma entidade fluida que requer estratégias sofisticadas de translocação. Entender como migrar JD não é mais um exercício acadêmico; é a pedra angular de uma inteligência artificial robusta.
Mais Artigos …
Página 1 de 18