
Todo sistema JD Edwards com alguns anos de uso carrega uma pergunta sem resposta fácil: quantos dos objetos customizados desenvolvidos ao longo do tempo ainda são fundamentalmente idênticos ao padrão Oracle do qual derivam, e quantos evoluíram a ponto de se tornarem algo completamente diferente? Essa pergunta se torna urgente quando se enfrenta um upgrade, uma migração ou uma auditoria das customizações. Na maioria dos casos, a resposta não existe — porque ninguém jamais a buscou de forma sistemática. Neste artigo, descrevo como abordo esse problema no meu trabalho e a ferramenta proprietária que desenvolvi para resolvê-lo.
O que é JD Edwards e por que esse problema existe?
JD Edwards (comumente conhecido como JDE) é um ERP corporativo desenvolvido pela Oracle, amplamente utilizado em empresas de manufatura, distribuição e nos setores de óleo e gás e construção. Como todos os sistemas ERP de alto nível, o JDE oferece um conjunto de objetos "padrão" — aplicações, relatórios, business functions e business views — que cobrem os processos de negócio fundamentais.
A realidade operacional, porém, é que nenhuma empresa usa o JDE puro. Cada implementação traz dezenas, senão centenas, de customizações: objetos padrão são copiados, renomeados com um prefixo customizado (tipicamente na faixa 55–69 conforme a nomenclatura JDE), e modificados para se adaptar aos processos específicos do cliente.
Isso cria um problema muito concreto: como saber, anos depois, qual padrão está na base de um objeto customizado? A rastreabilidade se perde. Os desenvolvedores mudam. A documentação envelhece ou não existe.
O problema técnico: encontrar a origem de um objeto customizado
No meu trabalho de consultoria JDE, frequentemente preciso analisar repositórios inteiros de objetos customizados — às vezes centenas de arquivos — para responder a perguntas como:
- Este P55001 é uma cópia do P4210? E o quanto ele se distanciou?
- Esta Business Function ainda é fundamentalmente idêntica ao padrão, ou foi reescrita?
- Quais objetos foram modificados de forma substancial e quais ainda correspondem ao original?
O problema não é trivial por diversas razões.
O conteúdo é ruidoso. Os exports do JDE contêm uma grande quantidade de boilerplate: comentários padrão, cabeçalhos de copyright, declarações de estrutura repetitivas. Se o texto bruto for comparado, o ruído supera o sinal.
Os nomes não são suficientes. Um P554210 provavelmente deriva do P4210, mas um P55001 pode derivar de P4101, P4201 ou de um objeto completamente diferente. A convenção de nomenclatura nem sempre é seguida, e em alguns casos o prefixo customizado não segue nenhuma lógica em relação ao original.
A escala torna a comparação manual inviável. Com 200 padrões e 400 objetos customizados, uma comparação manual gera 80.000 combinações possíveis. Isso não é uma operação humana.
A abordagem: um motor de análise híbrido
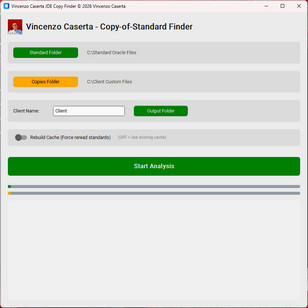
Para resolver esse problema, desenvolvi o COS-Analysis, uma ferramenta desktop proprietária que aborda a comparação em três níveis distintos, combinados em uma pontuação ponderada final.
Nível 1 — Limpeza e normalização do conteúdo
Antes de qualquer comparação, cada arquivo passa por uma fase de pré-processamento:
- Remoção do boilerplate fixo (cabeçalhos de copyright, declarações estruturais repetitivas específicas do JDE)
- Remoção do ruído de layout (posições, dimensões, identificadores de UI)
- Substituição do nome específico do objeto por um placeholder genérico, de modo a neutralizar as diferenças de nomenclatura durante a comparação textual
Esta etapa é crítica: sem normalização, dois objetos com comportamento idêntico mas com cabeçalhos de copyright diferentes pareceriam distintos, e dois objetos diferentes com o mesmo nome poderiam parecer artificialmente similares.
Nível 2 — Comparação do conteúdo textual via WinnowingAlgoritmo de fingerprinting documental: representa cada texto como um conjunto de hashes extraídos de janelas deslizantes de sequências de caracteres. Originalmente desenvolvido para detecção de plágio acadêmico, é robusto a modificações parciais do texto.
O núcleo da comparação textual é baseado no algoritmo WinnowingAlgoritmo de fingerprinting documental: representa cada texto como um conjunto de hashes extraídos de janelas deslizantes de sequências de caracteres. Originalmente desenvolvido para detecção de plágio acadêmico, é robusto a modificações parciais do texto., uma técnica de fingerprinting documental originalmente desenvolvida para detecção de plágio acadêmico. A ideia é representar cada documento como um conjunto de fingerprints de k-gramasUm k-grama é uma sequência contígua de k caracteres (ou tokens) extraída de um texto. Por exemplo, com k=4, a palavra "HELLO" gera os k-gramas: HELL, ELLO. O fingerprinting em k-gramas permite comparar textos mesmo quando foram parcialmente modificados. textuais, extraídos por meio de uma janela deslizante.
Essa abordagem tem uma vantagem fundamental em relação ao TF-IDFTerm Frequency–Inverse Document Frequency: técnica estatística que mede a relevância de uma palavra em um documento em relação a uma coleção. Palavras muito frequentes recebem peso baixo; palavras raras e específicas recebem peso alto. clássico (que uso como fallback): é robusto a transformações parciais. Se um objeto foi modificado apenas em algumas seções, o Winnowing ainda detecta a sobreposição estrutural nas partes inalteradas, produzindo uma pontuação de similaridade significativa mesmo na presença de modificações substanciais.
A parte computacionalmente mais pesada do Winnowing é implementada por meio de um módulo nativo compilado em Rust, integrado ao Python. Isso reduz significativamente os tempos de análise em repositórios grandes em comparação com uma implementação puramente Python.
Nível 3 — Fingerprint estruturalUma "impressão digital" do objeto JDE: em vez de comparar o texto completo, extrai-se um conjunto reduzido de tokens semanticamente significativos (forms, tabelas, views, joins) que representam a estrutura lógica do objeto, independentemente do código. via JaccardO índice de Jaccard mede a similaridade entre dois conjuntos: é a razão entre os elementos em comum (interseção) e o total de elementos distintos (união). Valor 1 = conjuntos idênticos, valor 0 = nenhum elemento em comum.
A comparação textual sozinha não é suficiente. Dois objetos JDE podem ter conteúdo textual similar, mas estrutura completamente diferente. Por isso, adicionei uma segunda camada baseada no conceito de structural fingerprintUma "impressão digital" do objeto JDE: em vez de comparar o texto completo, extrai-se um conjunto reduzido de tokens semanticamente significativos (forms, tabelas, views, joins) que representam a estrutura lógica do objeto, independentemente do código.: um conjunto de tokens semanticamente relevantes extraídos do arquivo.
Para cada tipo de objeto JDE, o conjunto de tokens é diferente:
- Para APPL: Form ID e Business View associada
- Para UBE: View e Report Interconnect
- Para BSVW: tabelas e definições de join
- Para BSFN: nome da função interna e DSTR associada
A similaridade entre os dois conjuntos de tokens é calculada por meio do índice de JaccardO índice de Jaccard mede a similaridade entre dois conjuntos: é a razão entre os elementos em comum (interseção) e o total de elementos distintos (união). Valor 1 = conjuntos idênticos, valor 0 = nenhum elemento em comum. (razão entre interseção e união), que mede o quanto os dois objetos compartilham a mesma "anatomia", independentemente de como o código está escrito.
Nível 4 — Meta-lógica sobre o nome normalizado
O quarto componente é mais simples, mas tem um impacto importante na precisão. Cada objeto customizado é analisado para identificar seu "pai teórico": removendo o prefixo numérico customizado do nome (ex. P55 → P, R564 → R), obtém-se o nome do objeto padrão do qual ele muito provavelmente deriva.
Se essa correspondência existir no repositório de padrões, a pontuação do candidato correspondente recebe um bônus ponderado. Esse mecanismo reduz drasticamente os falsos positivos nos casos em que a convenção de nomenclatura foi respeitada.
A pontuação final e a classificação
Os três componentes — Winnowing, Jaccard estrutural e meta-lógica — são combinados com pesos definidos para produzir uma pontuação final de similaridade entre 0 e 1. O resultado é então classificado em quatro categorias:
| Limiar | Classificação |
|---|---|
| ≥ 0,95 | Cópia idêntica / Exact Copy |
| ≥ 0,75 | Cópia com modificações menores |
| ≥ 0,50 | Cópia com modificações substanciais |
| < 0,50 | Objeto novo |
Para cada correspondência, a ferramenta gera automaticamente o comando de comparação para o Beyond Compare (uma ferramenta de diff muito utilizada no ecossistema JDE), permitindo que o analista abra imediatamente o diff visual entre o objeto customizado e seu padrão de referência com um único clique.
Resultados e uso prático
Ao final da análise, o COS-Analysis produz um relatório Excel com todos os resultados, ordenados por tipo de objeto e pontuação de similaridade decrescente. Cada linha inclui o nome do objeto analisado, a melhor correspondência padrão encontrada, o percentual de similaridade, a classificação e o comando Beyond Compare pronto para uso.
Na minha prática diária, esse relatório se torna o ponto de partida para as atividades de upgrade assessment, gap analysis e documentação das customizações. Em contextos onde se enfrenta uma migração para uma nova release do JDE, saber com precisão quais objetos customizados ainda estão próximos do original e quais se distanciaram significa planejar as atividades de reengenharia de forma informada, não intuitiva.
Conclusões
O problema da identificação das cópias dos padrões JDE é um problema real, recorrente e frequentemente subestimado no planejamento de projetos. A abordagem híbrida multinível que implementei no COS-Analysis — combinando pré-processamento semântico, Winnowing com motor Rust, similaridade estrutural Jaccard e meta-lógica sobre nomenclatura — permite obter resultados precisos mesmo em repositórios de grande porte, em tempos que tornam a análise viável.
Se você gerencia um sistema JDE e enfrenta esses desafios, estou disponível para conversar.
