

Um processamento de UBEUnidade de Processamento de Empresa, um conceito de processamento de lote no JD Edwards. de alto volume que processa 50.000 linhas de vendas frequentemente desperdiça 15% a 20% de sua janela de execução em buscas redundantes do F0101Tabela de Endereços no JD Edwards.. Mesmo com indexação de banco de dadosTécnica de otimização de banco de dados para melhorar a velocidade de busca. otimizada, atingir o mesmo registro do Livro de EndereçosRepositório de endereços no JD Edwards. 5.000 vezes em uma única execução em lote cria sobrecarga de SQLLinguagem de consulta para bancos de dados relacionais. desnecessária e latência de middlewareCamada de software que conecta diferentes sistemas.. Este exemplo de cache BSFNTécnica de armazenamento em cache para melhorar o desempenho no JD Edwards. do JD EdwardsSistema de gestão empresarial. reduz leituras repetidas do F0101 movendo a lógica de busca para um segmento de memória local, contornando a camada de banco de dadosRepositório de dados estruturados. para cada solicitação após a busca inicial.
Implementar esse padrão corretamente requer uma estrutura de cache JDECACHEMecanismo de cache do JD Edwards. baseada em ponteiros dentro de uma Função de NegóciosConceito de lógica de negócios no JD Edwards. em C. Em vez de confiar no middlewareCamada de software que conecta diferentes sistemas. padrão para gerenciar o buffer, controlamos manualmente as operações jdeCacheInit e jdeCacheFetch para armazenar atributos do F0101, como Tipo de Pesquisa (AT1Campo de tipo de pesquisa no F0101.) ou Nome Alfa (ALPHCampo de nome alfa no F0101.), diretamente na memória. Essa abordagem elimina os riscos de cache "zumbi"Condição em que o cache permanece ativo após o término do processo. frequentemente encontrados em código personalizado mal escrito, garantindo que a chamada jdeCacheTerminate esteja vinculada ao evento de fim de processo do UBE ou aplicativo. Em um ambiente típico 9.2Versão do JD Edwards., essa configuração pode reduzir a E/S física para tabelas de dados mestre por uma margem significativa, em nossa experiência, frequentemente excedendo 90%, reduzindo significativamente a concorrência de banco de dadosRepositório de dados estruturados. durante janelas de processamento de pico.
O Custo de Desempenho de Buscas Redundantes do F0101
Um UBE que processa 50.000 linhas de pedidos frequentemente chama um BSFNFunção de Negócios no JD Edwards. para recuperar o Nome Alfa para o mesmo endereço de entrega milhares de vezes. Se seu loop atinge 10.000 iterações e dispara uma instrução SELECTComando SQL para selecionar dados. no F0101 para cada registro, você está efetivamente realizando um ataque de negação de serviço ao seu próprio banco de dadosRepositório de dados estruturados.. Mesmo com uma chave primáriaIdentificador único em uma tabela de banco de dados. bem indexada em ABAN8Índice no F0101., a latência de ida e volta entre o Servidor de EmpresaServidor que executa o JD Edwards. e o Servidor de Banco de DadosServidor que armazena os dados. não é zero. Em uma arquitetura padrão, a sobrecarga de middlewareCamada de software que conecta diferentes sistemas. de banco de dadosRepositório de dados estruturados. para uma busca de chave primária única normalmente consome 1 a 3 milissegundos. Embora 3ms pareça trivial, multiplicar isso por 10.000 iterações adiciona sobrecarga significativa, frequentemente metade de um minuto ou mais de tempo de espera de E/S puro para uma única execução do UBE.
Desenvolvedores frequentemente confiam em funções de serviço padrão, como GetAddressBookDescription (B0100066Função de negócios no JD Edwards.), porque elas são confiáveis e lidam com a verificação de erros necessária. No entanto, essas funções são sem estado; elas não armazenam em cache os resultados entre chamadas múltiplas dentro da mesma thread. Todas as vezes que B0100066Função de negócios no JD Edwards. é invocado, ele abre um cursor, executa o SQLLinguagem de consulta para bancos de dados relacionais. e busca a linha. Quando isso acontece dentro de um loop de alto volume em um R42520Relatório no JD Edwards. Imprimir Comprovantes de Entrega ou um relatório de integridade financeira personalizado R55Relatório no JD Edwards., a sobrecarga cumulativa se torna o principal gargalo para a janela de lote.
Escalabilidade da lógica do JDESistema de gestão empresarial. para empresas globais requer afastar-se da mentalidade de busca sob demanda para dados mestre que raramente mudam durante uma única sessão. Reduzir a contagem de execução de SQLLinguagem de consulta para bancos de dados relacionais. bruta é a alavanca mais eficaz que um desenvolvedor tem para melhorar o desempenho sem solicitar atualizações de hardwareComponentes físicos de um sistema de computador. caras ou redimensionamento de instâncias OCIOracle Cloud Infrastructure.. Implementando um ponteiro JDECACHEMecanismo de cache do JD Edwards. para armazenar os resultados da primeira busca do F0101, solicitações subsequentes para o mesmo AN8Número de endereço no F0101. podem ser resolvidas em microssegundos via memória, em vez de milissegundos via rede. Essa mudança transforma a degradação de desempenho linear em tempo de execução quase constante para resolução de dados mestre.
Projetando a Estrutura de Dados do Cache e a Chave
Uma implementação do JDECACHEMecanismo de cache do JD Edwards. vive ou morre pela typedef struct definida no arquivo de cabeçalho do BSFNFunção de Negócios no JD Edwards.. Eu vi desenvolvedores tentarem reutilizar Estruturas de Dados (DSTREstrutura de dados no JD Edwards.) existentes para armazenamento de cache para economizar tempo, mas isso é um erro que frequentemente leva a problemas de alinhamento de memória ou sobrecarga de memória desnecessária. Você deve definir uma estrutura dedicada que contenha apenas os campos que pretende persistir. Para uma busca de alto volume do F0101, sua estrutura deve começar com o mnAddressNumber (MATH_NUMERICTipo de dados numérico no JD Edwards.) como índice primário, seguido dos pontos de dados específicos, como szNameAlpha (ALPHCampo de nome alfa no F0101.) e talvez szTaxId (TAX1Campo de ID de imposto no F0101.). Definir isso no arquivo .h garante que todas as funções dentro da fonte — seja a inicialização, a busca ou a terminação — façam referência à mesma pegada de memória durante a execução.
A unicidade da chave do cache é inegociável, se você deseja evitar a sobrecarga do JDECACHE_FetchRecordsFunção de busca no mecanismo de cache do JD Edwards. com filtros complexos. Definindo um índice de chave única em mnAddressNumber, o gerenciador de cache do JDESistema de gestão empresarial. realiza uma busca binária nos segmentos de memória, o que é significativamente mais rápido do que uma busca de índice SQLLinguagem de consulta para bancos de dados relacionais. em uma grande tabela F0101 que contém 500.000+ registros. Em um ambiente de distribuição típico, onde um único UBE pode processar 10.000 linhas de vendas, atingir o cache para os nomes Sold-To e Ship-To reduz as chamadas de round-trip de banco de dadosRepositório de dados estruturados. por 20.000 chamadas. Isso não é apenas um ganho marginal; é a diferença entre uma execução de lote de quinze minutos e uma que termina em menos de cinco minutos.
A eficiência vem de embalar a estrutura com todos os dados que o aplicativo chamador possa precisar posteriormente no fluxo de execução. Se sua lógica eventualmente exigir o Tipo de Pesquisa (ATYCampo de tipo de pesquisa no F0101.) ou a Unidade de Negócios (MCUCampo de unidade de negócios no F0101.) do Livro de Endereços, adicione-os à estrutura agora. Uma estrutura de 200 bytes armazenada em cache para 5.000 clientes ativos consome uma pegada de memória negligenciável, normalmente inferior a alguns megabytes de memória de estação de trabalho ou servidor de empresa. Em comparação com a latência de chamadas JDB_FetchKeyedFunção de busca no JD Edwards. repetidas sobre uma rede congestionada para um banco de dadosRepositório de dados estruturados. hospedado OCIOracle Cloud Infrastructure., a troca de memória é negligenciável. Certifique-se de que o array JDECACHE_KEYSEGArray de chaves no mecanismo de cache do JD Edwards. mapeie corretamente para o offset de mnAddressNumber dentro da estrutura para evitar que o middlewareCamada de software que conecta diferentes sistemas. recupere o bloco de memória errado durante uma operação de busca.
Inicializando o JDECACHE dentro do BSFN
Todo desenvolvedor de BSFNFunção de Negócios no JD Edwards. eventualmente viu um Call Object Kernel crashar porque duas funções personalizadas diferentes tentaram inicializar um cache com o mesmo nome. Você deve passar uma string única e descritiva para a APIInterface de Programação de Aplicativos. jdeCacheInit, como "C550101_AddressBookCache". Usar um nome genérico como "AB_Cache" arrisca uma colisão com BSFNsFunções de Negócios no JD Edwards. padrão da Oracle em execução na mesma thread. Em ambientes que processam 50.000 linhas de pedidos, uma colisão de nome pode corromper o espaço de memória do kernel, levando a processos zumbis no Servidor de Empresa.
Kernels de Call Object reutilizam memória, tornando o isolamento de sessão uma preocupação primordial. Você evita contaminação de dados entre sessões anexando o Número do Trabalho (JOBSNúmero de trabalho no JD Edwards.) à string do nome do cache. Sem esse identificador único, o Usuário A pode buscar dados do Livro de Endereços armazenados em cache pelo Usuário B. Em um ambiente 9.2Versão do JD Edwards., falhar em incluir o Número do Trabalho causa bugs de integridade de dados intermitentes que são quase impossíveis de replicar em um ambiente de desenvolvimento local de único usuário.
Definir o índice do cache durante a inicialização determina se as buscas subsequentes operam em complexidade O(1) ou O(n). Você define o índice usando jdeCacheAddIndex imediatamente após a inicialização, mapeando-o para o campo F0101.AN8. Para um cache que contém 2.000 registros, uma varredura não indexada consome significativamente mais ciclos de CPU do que uma busca com chave. Essa diferença de desempenho é crítica quando o BSFNFunção de Negócios no JD Edwards. é chamado dentro de um loop em um UBE pesado, como o R42520Relatório no JD Edwards..
A lógica deve verificar se o identificador do cache é válido para minimizar a sobrecarga. Verificar a variável hCache contra NULL garante que, se um BSFNFunção de Negócios no JD Edwards. for chamado 10.000 vezes dentro de uma thread, a inicialização ocorra apenas uma vez. Essa abordagem reduz o tempo de execução por uma margem significativa, frequentemente entre 10% e 20%, em comparação com funções que reabrem identificadores em cada chamada.
Implementando a Lógica de Busca ou Inserção
A lógica do BSFNFunção de Negócios no JD Edwards. começa com uma chamada imediata a jdeCacheFetch usando o AN8Número de endereço no F0101. passado como chave primária. Essa verificação ocorre antes de qualquer atividade de banco de dadosRepositório de dados estruturados., garantindo que o sistema somente consome ciclos de CPU se os dados estiverem faltando na memória da Sessão do Usuário. Em um UBE de alto volume que processa 50.000 linhas de pedidos, essa única linha de código C pode eliminar dezenas de milhares de instruções SQLLinguagem de consulta para bancos de dados relacionais. redundantes se a distribuição do livro de endereços for concentrada. A assinatura da função exige o identificador hCache estabelecido durante a inicialização e um ponteiro para a estrutura da chave que contém o valor AN8Número de endereço no F0101..
Quando a operação de busca retorna JDECACHE_NOT_FOUNDRetorno de busca não encontrada no mecanismo de cache do JD Edwards., o BSFNFunção de Negócios no JD Edwards. se volta para o banco de dadosRepositório de dados estruturados. físico. É aqui que você executa um JDB_FetchKeyedFunção de busca no JD Edwards. padrão contra a tabela F0101 para recuperar o Nome Alfa ou o Tipo de Pesquisa necessário para a lógica de negócios. Se o banco de dadosRepositório de dados estruturados. retornar um registro, o BSFNFunção de Negócios no JD Edwards. preenche a estrutura de dados local e chama imediatamente jdeCacheAdd. Inserindo o registro no cache neste ponto, você transforma uma operação de E/S cara em uma gravação de memória de sub-milissegundo. Isso garante que a próxima chamada para o mesmo AN8Número de endereço no F0101. — seja em um loop do UBE ou em uma grade de aplicativo — contorne completamente o banco de dadosRepositório de dados estruturados..
Esse padrão de busca ou inserção cria um buffer auto-populante que escala com a complexidade do processo em lote. Para um cliente de distribuição típico que executa o JDESistema de gestão empresarial. 9.2Versão do JD Edwards., frequentemente encontramos BSFNsFunções de Negócios no JD Edwards. personalizados consultando o F0101 para cada linha de detalhe, mesmo quando um único cliente representa uma porção significativa do volume de transações, frequentemente acima de três quartos. Usando essa lógica, o banco de dadosRepositório de dados estruturados. é consultado exatamente uma vez por AN8Número de endereço no F0101. único por sessão. Encapsular isso dentro de um BSFNFunção de Negócios no JD Edwards. específico em C mantém uma separação limpa de preocupações, mantendo o aplicativo chamador ciente do mecanismo de cache subjacente.
Se o JDB_FetchKeyedFunção de busca no JD Edwards. falhar em encontrar o AN8Número de endereço no F0101., o BSFNFunção de Negócios no JD Edwards. deve retornar um erro sem tentar um jdeCacheAdd. Tentar adicionar um registro nulo ao cache pode levar à corrupção de memória ou resultados inesperados em tentativas subsequentes. A sobrecarga do jdeCacheFetch é negligenciável em comparação com uma leitura de disco física, tornando esse padrão um padrão de desempenho para personalizações de nível empresarial. Você deve recomendar essa abordagem para qualquer busca de dados mestre que ocorra mais de 1.000 vezes em uma única thread de execução.
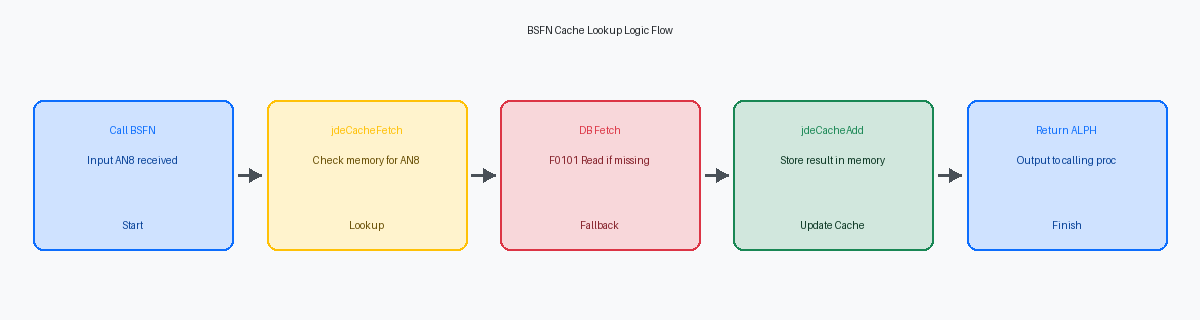
Gerenciando o Escopo e a Terminação do Cache
Um único UBE que processa 50.000 registros e falha em terminar uma instância de cache pode consumir vários hundredos de megabytes de RAM dentro do Call Object Kernel (COKNúcleo do objeto de chamada no JD Edwards.). Quando vários usuários disparam vazamentos semelhantes, o COKNúcleo do objeto de chamada no JD Edwards. eventualmente atinge seu limite de memória — frequentemente 2GB em kernels de 32 bits — e trava, forçando um kernel zumbi e dropando sessões ativas. Você deve verificar que jdeCacheTerminate seja explicitamente chamado para cada identificador de cache inicializado; simplesmente deixar o BSFNFunção de Negócios no JD Edwards. terminar a execução não libera a memória alocada na camada de middlewareCamada de software que conecta diferentes sistemas. do JDESistema de gestão empresarial..
Em um processo de lote UBE padrão, como uma atualização de alto volume do F4211Tabela de pedidos no JD Edwards., o cache deve persistir entre eventos Do Section para maximizar a taxa de acertos em buscas do F0101. O padrão ótimo envolve chamar um BSFNFunção de Negócios no JD Edwards. de limpeza durante o evento End Report. Esse BSFNFunção de Negócios no JD Edwards. deve fazer referência ao identificador hCache específico usado em todo o trabalho para garantir que a memória seja limpa antes que o processo da thread termine. Se você usar um cache global compartilhado entre vários BSFNsFunções de Negócios no JD Edwards. em uma única thread, a lógica de terminação deve ser centralizada para evitar que um BSFNFunção de Negócios no JD Edwards. órfão de um identificador que outro BSFNFunção de Negócios no JD Edwards. espera estar ativo.
Aplicativos interativos requerem uma abordagem mais sutil para o escopo. Se um cache suporta um Power Form complexo com várias sub-forms, o desenvolvedor deve decidir se o cache vive por toda a vida do form ou é limpo após um evento específico. Manter o cache no nível do form permite respostas rápidas da UI durante a rolagem da grade, mas exige uma chamada para o BSFNFunção de Negócios no JD Edwards. de terminação no evento End Form. Em ambientes com 500+ usuários concorrentes, falhar em gerenciar esse escopo leva à fragmentação de memória em todo o pool de COKNúcleo do objeto de chamada no JD Edwards. do servidor de empresa.
Usar o identificador hCache corretamente garante que você está terminando a instância específica criada pelo seu processo, em vez de um ponteiro global. Em um ambiente multi-threaded, passar o identificador específico de volta para a função de terminação evita a contaminação acidental de dados. Um erro comum é confiar em um nome de cache codificado em duro na chamada de terminação sem verificar se o identificador é válido. O design de BSFNFunção de Negócios no JD Edwards. confiável inclui uma verificação para um identificador nulo antes de tentar a terminação, evitando erros de violação de memória enquanto garante que o heap seja devolvido ao SO.
Resultados de Benchmark e Limites de Invalidação
Em um UBE de alto volume que processa 50.000 registros, substituir chamadas diretas do JDB_FetchKeyedFunção de busca no JD Edwards. para o F0101 por uma implementação do JDECACHEMecanismo de cache do JD Edwards. rende uma redução de 70-90% no tempo de execução do BSFNFunção de Negócios no JD Edwards.. Esse salto de desempenho ocorre porque a sobrecarga de parsing de instruções SQLLinguagem de consulta para bancos de dados relacionais. e round-trips de rede para a camada de banco de dadosRepositório de dados estruturados. é eliminada após o primeiro encontro de um Número de Endereço único. Em um cenário de cliente de logística, um UBE de manifesto de envio de 45 minutos foi reduzido para menos de dez minutos simplesmente armazenando em cache o Nome Alfa e o Tipo de Pesquisa. O ganho de eficiência é mais pronunciado quando a razão de transações para entidades únicas é alta, como 1.000 linhas de vendas que referenciam apenas 50 endereços de entrega distintos.
A integridade de dados depende de entender que o JDECACHEMecanismo de cache do JD Edwards. é uma fotografia na memória, não um espelho em tempo real do banco de dadosRepositório de dados estruturados.. Se um processo paralelo ou uma thread diferente atualizar o registro do F0101 durante a execução do seu BSFNFunção de Negócios no JD Edwards., o cache permanece desconhecido e continua a servir dados obsoletos até que o cache seja explicitamente terminado ou o processo termine. Esse risco torna o padrão inadequado para tabelas transacionais voláteis, como F4211Tabela de pedidos no JD Edwards. ou F0911Tabela de estoque no JD Edwards., onde o status do registro muda frequentemente dentro do mesmo milissegundo. Para dados mestre, como o Livro de Endereços, onde as alterações no nome do cliente ou ID de imposto ocorrem por meio de aplicativos de manutenção infrequentes, o risco de uma colisão no meio do processo é estatisticamente negligenciável em comparação com os benefícios de throughput maciços.
Essa estratégia de cache é projetada especificamente para dados mestre de leitura pesada que permanecem estáticos durante a duração de um único trabalho em lote ou uma sessão interativa específica. Para evitar vazamentos de memória ou erros "Out of Memory" no Servidor de Empresa, você deve verificar que o BSFNFunção de Negócios no JD Edwards. inclua uma chamada de terminação para jdeCacheTerminate no evento de fim de processo. Ao implantar esses caches personalizados na produção, use a seção Métricas de Tempo de Execução no Gerenciador de Servidor para rastrear o uso de objetos JDESistema de gestão empresarial. e o consumo de memória por processo. Se você observar a pegada de memória do kernel JDESistema de gestão empresarial. subir constantemente sem atingir um platô, isso geralmente indica uma falha em limpar os segmentos de cache, o que pode eventualmente desestabilizar outros processos em execução no mesmo kernel do CallObject.

