
O que é realmente um Dashboard de risco de retrofit
Na essência, é uma pontuação de risco por objeto, calculada antes do início do trabalho de retrofit e apresentada de uma forma que a equipe possa usar para priorizar. As entradas vêm de três lugares: o resultado da etapa Custom Code AnalyzerO conceito técnico que produz o veredito por objeto — manter, fazer retrofit, descartar, reescrever. Sua saída é a principal entrada do dashboard., a telemetria runtime do ambiente de origem e o grafo de dependências dos objetos JDE afetados. A saída é um valor único por objeto — de 1 a 10, verde/amarelo/vermelho ou outra escala — mais o detalhamento do que levou a esse valor.
Um número único importa porque uma janela de desenvolvimento de 9 semanas tem aproximadamente 70 dias úteis para a equipe de desenvolvimento. Com 350 objetos impactados, isso dá cerca de cinco horas por objeto em média, incluindo testes. Um dashboard desse tipo mostra quais objetos merecem um dia e quais merecem quinze minutos. Sem ele, todos os objetos recebem a mesma alocação; os perigosos são pouco testados e os triviais são superengenheirados.
A parte “dashboard” do nome também importa. Não é uma lista, não é um veredito — é uma visão que o gerente de projeto e o lead developer olham toda segunda-feira de manhã para decidir para onde irão as próximas duas semanas de esforço. Estática no começo, depois atualizada conforme o retrofit avança e as premissas são validadas.
Por que essa disciplina surgiu
Porque a alternativa — tratar o trabalho de retrofit como uma lista plana de 350 itens, todos com o mesmo peso — tem um modo de falha previsível. A equipe começa pelo topo em ordem alfabética, consome as primeiras seis semanas nos UBEsUniversal Batch Engine — o executor de relatórios batch do JDE. UBEs customizados são os objetos mais numerosos e geralmente os de menor risco em um conjunto de retrofit. customizados fáceis dos prefixos A e B, e descobre na semana sete que as três BSFNsBusiness Functions — código C compilado no runtime JDE. Elas ficam na base do grafo de dependências e quebram tudo quando falham. customizadas no centro do fluxo de order entry são inviáveis na forma atual. Nesse ponto, o orçamento já acabou.
O dashboard de risco inverte isso. Os objetos mais perigosos são trabalhados primeiro, quando a equipe ainda está fresca e ainda há tempo para escalar. Os triviais ficam na parte final do cronograma, onde um desenvolvedor júnior pode eliminar dez em um dia. Mesmo trabalho total, resultado completamente diferente na semana nove.
É também por isso que equipes com PMs fortes gravitam para essa disciplina mesmo quando nenhum artefato formal existe. Elas reconstroem o dashboard mentalmente, em um quadro branco ou em uma planilha meio quebrada — porque sem ele o upgrade entra em produção atrasado ou quebrado, e elas já viram os dois cenários.
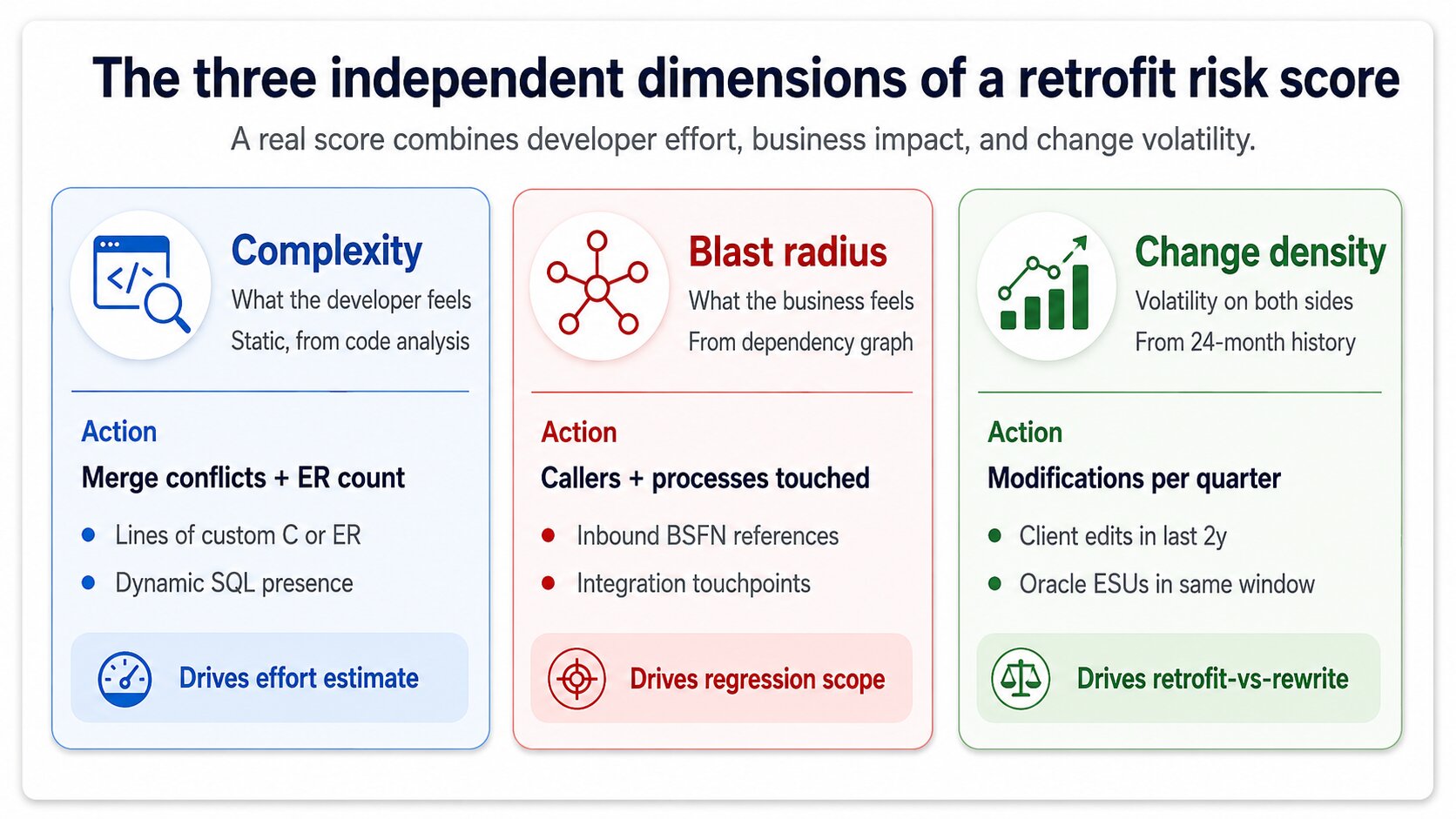
As três dimensões de entrada de uma pontuação real de risco
Uma pontuação com uma dimensão é um palpite. Uma pontuação com três é um julgamento técnico defensável. As três que realmente importam são complexidade, blast radius e change density, e um dashboard de risco sério calcula as três de forma independente antes de combiná-las.
Complexidade é o que o desenvolvedor sente. Número de conflitos de merge previstos pela etapa de fingerprint, linhas de código customizado no objeto, presença de Event RulesA camada de scripting visual do JDE associada a formulários e aplicações. Retrofit de Event Rules é mais difícil do que retrofit de código C porque o diff é visual, não textual. em vez de C simples, presença de SQL dinâmico. Uma BSFN customizada com 40 linhas de C inalterado e uma variável renomeada é complexidade 1. Uma aplicação customizada com 200 Event Rules e mudanças Oracle conflitantes em três subforms é complexidade 9.
Blast radius é o que o negócio sente. Quantos outros objetos dependem deste, quantos processos de negócio passam por ele, quantas integrações o chamam. Um UBE customizado que ninguém executa tem blast radius 1 mesmo que seu código seja complicado. Uma BSFN customizada chamada por 47 aplicações em order entry, manufatura e finanças tem blast radius 9 mesmo que seu código seja trivial de mesclar. As duas dimensões são independentes, e um bom dashboard nunca as colapsa cedo demais.
Change density é o sinal de volatilidade. Com que frequência o objeto do ambiente de origem foi modificado nos últimos 24 meses e quantos ESUs a Oracle entregou para o equivalente padrão no mesmo período. Alta change density dos dois lados significa que retrofits futuros ficam mais difíceis, não apenas este — a pontuação deve refletir o custo estratégico de fazer retrofit versus reescrever sobre a base Oracle atual.
Como a telemetria runtime refina a pontuação
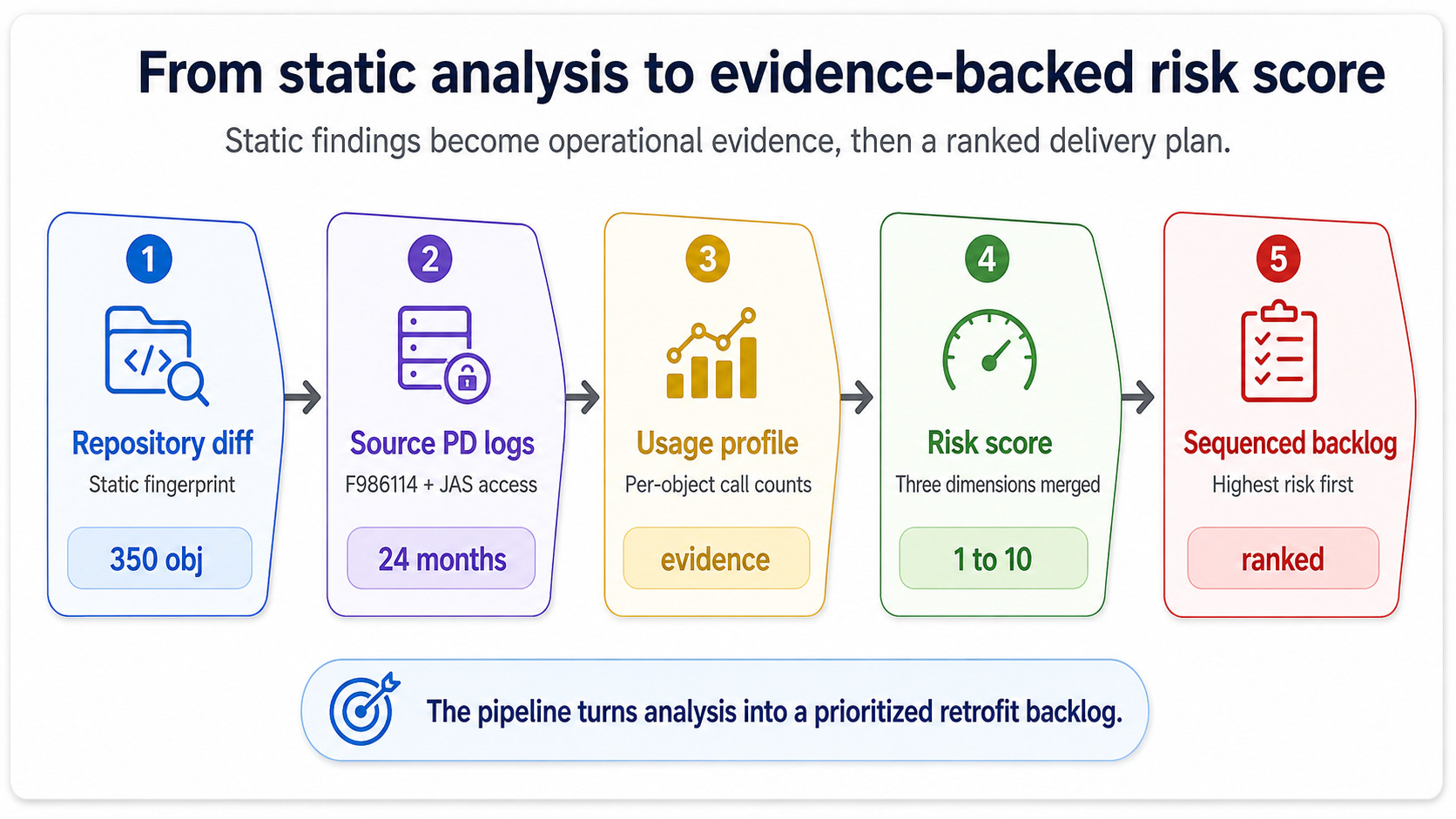
As dimensões acima podem ser calculadas estaticamente, a partir do repositório e do histórico de mudanças. O dashboard de risco se torna útil — e não apenas um exercício acadêmico — quando você incorpora dados runtime do ambiente de origem.
O ambiente PDAmbiente de produção no JDE — o ambiente live. Logs de execução de PD são a fonte da verdade para saber quais objetos são realmente usados e com que frequência. de origem sabe coisas que a análise estática não sabe. Ele sabe quais UBEs customizados rodaram zero vezes no último trimestre, quais BSFNs customizadas foram chamadas 11 milhões de vezes e quais aplicações customizadas concentraram logs de erro nas semanas antes do início do planejamento de go-live. Extraia as contagens de execução da F986114Tabela de controle de jobs do JDE. Ela registra cada submissão de UBE e é a fonte canônica de telemetria de execução batch no ambiente de origem. para o lado batch e dos logs de acesso JAS para o lado interativo, e você terá um perfil de uso que transforma “blast radius” de estimativa em evidência.
É esse movimento que transforma o dashboard de uma planilha estática em algo que o gerente de projeto realmente confia. Uma pontuação verde sustentada por zero execuções é honesta. Uma pontuação verde que ignora 11 milhões de chamadas é um projeto esperando falhar no cutover.
Como o dashboard se apresenta no nível de artefato
A forma física varia — algumas equipes usam uma página Confluence, outras usam um relatório Power BI sobre um extrato SQL, as mais disciplinadas usam um CSV plano que qualquer pessoa consegue filtrar. A forma é irrelevante. O que importa é que, para cada um dos 350 objetos impactados, você consiga responder quatro perguntas em menos de um minuto.
Qual é a pontuação, e o que a gerou. Quem é o responsável por esse objeto durante o retrofit. Qual é o esforço planejado e qual é o escopo planejado de regressão. Qual é o estado atual — não iniciado, em desenvolvimento, em teste, aprovado. Se o dashboard não consegue responder essas quatro perguntas sob demanda para qualquer objeto, ele não é um dashboard de risco; é uma lista. A distinção não é pedante: listas não mudam comportamento, dashboards mudam.
Outro requisito no nível de artefato é que o dashboard seja atualizado. Uma estimativa de retrofit escrita na semana zero estará errada na semana três — alguns objetos serão mais difíceis, outros triviais — e o dashboard precisa absorver essas correções sem cerimônia. Equipes que tratam a pontuação inicial como verdade absoluta entregam tarde. Equipes que a tratam como hipótese em revisão contínua entregam no prazo.
Onde o dashboard se encaixa no restante do upgrade
Ele alimenta dois consumidores downstream. A equipe de desenvolvimento o usa para sequenciar o trabalho, pegando os objetos de maior pontuação na semana um e deixando os triviais para o fim do cronograma. A equipe de testes o usa para definir o escopo de regressão: objetos com alto blast radius puxam mais processos de negócio para a cobertura de regressão, enquanto objetos com baixo blast radius podem ser cobertos apenas por smoke tests automatizados.
O terceiro consumidor é o comitê de direção, e é aqui que a maioria das equipes subestima o artefato. O dashboard, consolidado em um gráfico de distribuição, diz ao CIO se o retrofit vai caber no escopo ou não — muito antes de a equipe de desenvolvimento expor essa informação pelo reporting normal de status. Um dashboard inclinado para o vermelho é uma conversa de orçamento na semana dois, não uma emergência na semana oito. Esse sinal precoce é a segunda saída mais valiosa da disciplina, depois da priorização do dia a dia.
Upstream, o dashboard depende inteiramente de as etapas de smart filter e fingerprint terem produzido uma saída limpa. Garbage in, dashboard inútil out. Por isso essa disciplina nunca vive isolada — ela é a terceira etapa de um pipeline de quatro etapas, e pular o trabalho anterior para ir direto ao scoring produz números em que ninguém confia.
O que isso significa para o seu escopo de upgrade
Se o parceiro responsável pelo seu retrofit não consegue mostrar um backlog pontuado por risco ou um equivalente defensável na semana um de desenvolvimento, você tem um problema que ainda não conhece. O artefato não precisa carregar esse nome — sinônimos como matriz de triagem de retrofit, backlog ponderado por impacto e ordem de trabalho pontuada por risco descrevem a mesma disciplina — mas as três dimensões de entrada e as quatro perguntas no nível de artefato não são negociáveis.
Peça para ver. Pergunte quais objetos tiveram a pontuação mais alta e por quê. Pergunte como a telemetria runtime do seu ambiente de origem foi incorporada. Se as respostas forem vagas, a equipe vai descobrir os objetos perigosos do jeito lento, no seu tempo. O custo dessa descoberta, em um ambiente típico de 9.1 para 9.2, fica em algum ponto entre três e seis semanas extras de desenvolvimento, além de um impacto perceptível na passagem dos testes de regressão.
Se você quer uma segunda opinião sobre se o seu plano atual de retrofit tem a estrutura de scoring e priorização necessária, agende uma consulta gratuita. Vamos percorrer as dimensões no seu ambiente específico, verificar onde a telemetria runtime vive no seu ambiente de origem e dizer honestamente se o trabalho à frente está corretamente ponderado — ou se o projeto está a uma semana ruim de uma conversa de orçamento.