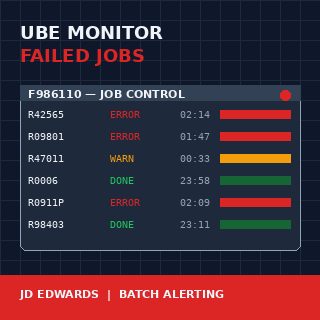
Um monitor de jobs batch do JD Edwards EnterpriseOne para relatórios UBE com falha é uma daquelas construções que se pagam no primeiro mês e continuam se pagando a cada fechamento trimestral depois disso. O console do Server Manager informa que um job terminou com erro, mas não acorda ninguém por causa disso, e também não informa que a execução de confirmação R42565 falhou pela terceira noite seguida às 02:14. Quando o supervisor do armazém liga às 7 da manhã perguntando por que nenhum pick slip foi impresso, os dados já estão quatro horas defasados e a manhã já foi perdida.
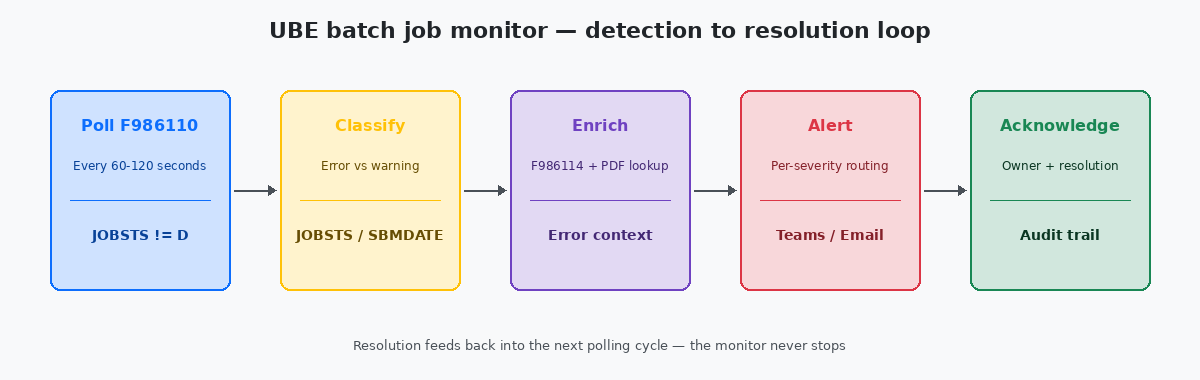
Toda instalação JDE madura com a qual trabalhei acaba construindo um desses monitores. Os que funcionam compartilham três propriedades: consultam F986110Job Control Master — a tabela JDE que registra cada submissão UBE, seu código de status, horários de início e fim, e o servidor em que ela foi executada. em uma cadência curta, classificam erros por impacto e roteiam alertas para canais compatíveis com a severidade. Os que falham geralmente são apenas por e-mail, disparam para tudo e são silenciados pela equipe de operações em até seis semanas.
O que "failed" realmente significa na F986110
O Job Control Master é a fonte única da verdade para execução batch no JDE E1. Cada submissão UBE grava uma linha aqui, identificada por JOBNBR, com uma coluna JOBSTS que percorre um pequeno conjunto de valores de caractere único: W (aguardando), P (processando), D (concluído), E (erro), CE (cancelado com erro), S (cancelado pelo usuário), H (retido). Um monitor ingênuo observa JOBSTS = E e alerta. Um monitor útil conhece a diferença entre E e CE, trata jobs H com mais de 30 minutos como um problema separado e reconhece que um job P que está processando há seis horas quando normalmente termina em doze minutos também é uma falha, apenas mais silenciosa.
As colunas SBMDATE e SBMTIME fornecem o timestamp da submissão; ENDDATE e ENDTIME fornecem a conclusão. O intervalo entre a submissão e a hora atual do sistema é o que permite sinalizar jobs travados. A coluna PID informa qual UBE era, o que importa porque a falha de R0006 (EDI inbound) tem consequências downstream diferentes da falha de R09801 (Post General Ledger), e o monitor precisa saber qual é qual.
A coluna SRVRNM informa qual enterprise server executou o job. Em uma instalação com vários servidores, isso não é uma informação cosmética — uma falha recorrente em um servidor enquanto os outros executam corretamente é um problema de infraestrutura, não um problema de UBE, e o monitor deve destacar esse padrão.
O loop de polling e por que o timing importa mais que a lógica
O monitor funcional mais simples é uma consulta SQL contra a F986110 executada a cada 60 a 120 segundos por um job agendado. Execute com mais frequência e você coloca carga no banco de dados sem benefício humano — ninguém vai reagir a um alerta em menos de um minuto de qualquer forma. Execute com menos frequência e você perde a capacidade de capturar falhas de ciclo curto antes que o próximo job dependente tente iniciar.
A consulta em si é direta: buscar cada linha em que JOBSTS esteja em ('E','CE') e ENDDATE seja maior ou igual ao high-water mark do ciclo de polling anterior. Controle o high-water mark em uma pequena tabela custom para que uma reinicialização do monitor não reproduza todos os erros dos últimos seis meses. O padrão é o mesmo princípio de idempotência que se aplica a qualquer carga de dados — executar o monitor duas vezes deve produzir um conjunto de alertas, não dois.
O ponto que a maioria dos builds perde é o tratamento de fuso horário. A F986110 armazena datas no formato juliano JDE e horários como valores inteiros HHMMSS, ambos no fuso horário do enterprise server. Se o monitor roda em outro host em outro fuso horário, a lógica de comparação precisa converter explicitamente. Já depurei um monitor que perdia silenciosamente todos os erros entre 23:00 e meia-noite porque a comparação cruzava uma fronteira de data do lado errado.
Classificar severidade sem escrever mil regras
O instinto no primeiro build é escrever uma regra por UBE. Quando você tem 40 regras, já tem uma bagunça impossível de manter, e quando chega a 200 ninguém sabe mais quais regras ainda se aplicam. O padrão que escala é severidade por categoria, não por job.
Três categorias cobrem aproximadamente 95% das instalações reais. Crítico significa com impacto em receita ou compliance: EDI inbound e outbound (R47*), confirmação de expedição de pedidos de venda (R42565), faturamento (R42565, R03B11Z1I), fechamento de período (R09801, R0911P, R09866), geração de folha de pagamento. Padrão significa com impacto no negócio, mas não no mesmo dia: relatórios de integridade de arquivos mestres, jobs de reorganização, monitores de replicação. Noisy significa erros que se repetem previsivelmente e geralmente são problemas de dados: relatórios de integridade sinalizando registros órfãos conhecidos, UBEs custom que frequentemente falham com entrada inválida.
A classificação fica em uma pequena tabela de lookup indexada por PID, com Standard como padrão para qualquer item não mapeado. Novas UBEs são adicionadas ao lookup como parte do checklist de promoção de desenvolvimento, não depois. O monitor lê o lookup uma vez por ciclo de polling e o mantém em cache pelo restante do ciclo.

Rotear alertas para canais que realmente são lidos
E-mail é onde alertas vão para morrer. A primeira versão de todo monitor que herdei enviava para uma lista de distribuição com doze pessoas; no terceiro mês, dez delas tinham uma regra no Outlook movendo as mensagens para uma pasta que ninguém abre. O padrão que funciona é o roteamento mapeado por severidade: alertas críticos vão para um sistema de paging com escala de plantão, alertas padrão vão para um canal dedicado no Teams ou Slack com a equipe de operações, alertas noisy vão para um e-mail digest diário que resume em vez de gerar spam.
O padrão do canal Teams é o carro-chefe para alertas padrão. Um webhook recebe um payload JSON com JOBNBR, PID, servidor, timestamp do erro e um link direto para a saída PDFO arquivo de saída UBE gerado para cada job batch, armazenado no diretório PrintQueue no enterprise server. O contexto do erro geralmente fica nas últimas páginas. e para o job log no console web do Server Manager. O link importa — sem ele, cada alerta custa cinco minutos de navegação antes que o engenheiro possa começar o diagnóstico. Com ele, o diagnóstico muitas vezes acontece diretamente a partir do alerta.
O sistema de paging, seja PagerDutyUma plataforma de resposta a incidentes amplamente usada, que gerencia escalas de plantão, alertas telefônicos, SMS e escalonamento automático quando os alertas não são reconhecidos dentro de uma janela definida., Opsgenie ou um dos equivalentes open source, deve disparar para aproximadamente cinco a dez PIDs no total, não para cada linha vermelha na F986110. Quanto menos jobs acordarem pessoas às 3 da manhã, mais credibilidade o monitor mantém. A lista de UBEs elegíveis para paging deve ser revisada a cada trimestre, porque alguns jobs se tornam críticos e outros deixam de ser.
A deduplicação de alertas é o detalhe que toda equipe erra no primeiro build. Quando o fechamento de período falha, ele não falha isoladamente — um erro no R09801 geralmente significa que R0911P e R09866 também falharão nos próximos dez minutos, porque dependem do mesmo estado de dados. Sem deduplicação, o engenheiro de plantão recebe quatro alertas para uma única causa raiz e precisa agrupá-los mentalmente. O padrão que funciona é uma janela de alerta de cinco minutos indexada por categoria e servidor, em que o monitor emite um alerta consolidado listando todas as falhas relacionadas em vez de disparar quatro vezes. Vinte linhas de lógica de agrupamento, melhoria mensurável no tempo médio até o reconhecimento.
Enriquecer alertas com o contexto de que o engenheiro de plantão realmente precisa
A diferença entre um alerta útil e um imposto sobre a atenção é o contexto anexado. Um simples "R42565 failed on server JDE_ENT01" força o engenheiro a fazer login no Server Manager, encontrar o job, baixar o PDF, abri-lo, rolar até o final e ler a stack de erro. Multiplique isso por cada alerta e o monitor vira um dreno de produtividade.
O enriquecimento que se paga vem da junção da F986110 com a F986114 (o detalhe das etapas do job) e da inclusão das últimas linhas do job log diretamente no payload do alerta. A mensagem de erro — "Invalid Branch/Plant for Item 30000" ou "Mandatory Processing Option PR1 not set" — informa ao engenheiro de plantão em cinco segundos se isso é um problema de dados (chamar o analista) ou um problema de código (chamar o desenvolvedor). Sem essa linha, cada alerta é um cara ou coroa.
A segunda peça de enriquecimento que escala é a detecção de recorrência. Se o mesmo PID falhou três noites seguidas aproximadamente no mesmo horário, o payload do alerta deve dizer isso. A correção raramente é a mesma de uma falha pontual, e o responsável precisa saber o que está olhando antes de começar. Uma pequena tabela de recorrência, indexada por PID e reiniciada semanalmente, tem cinquenta linhas de SQL e economiza horas por mês.
A última peça, muitas vezes ignorada, é o loop de reconhecimento. Quando o engenheiro de plantão corrige um job, ele deve poder marcar o alerta como resolvido com um comentário curto — "PO bad data, fixed in F4311 batch 1207" — e esse comentário deve cair em uma pequena tabela de histórico do monitor. Três meses depois, quando a mesma UBE falha no mesmo dia do mês, o próximo responsável vê a resolução anterior e reconhece o padrão em trinta segundos, em vez de começar do zero. A trilha de auditoria também dá ao gerente de operações algo concreto para colocar no relatório trimestral de estabilidade: não "o monitor capturou 247 erros", mas "247 erros, tempo médio de reconhecimento de 11 minutos, três principais ofensores R47011, R42565, R09801, todos corrigidos dentro do SLA". Esses são os dados que justificam o build.
Se o monitoramento batch é o tipo de disciplina operacional que você quer ampliar, os artigos relacionados sobre configuração do JDE Server Manager, design de checkpoint e restart de UBE e estratégias de arquivamento da F986110 cobrem a stack operacional pelo outro lado. O portfólio de projetos técnicos deste site documenta dois dos monitores de produção que produziram os padrões descritos aqui.