A pergunta mais difícil de responder em qualquer instalação JDE madura é uma das mais simples de fazer: "se eu alterar esta tabela, qual aplicação custom quebra?" Mapear dependências de business views em aplicações custom do JD Edwards EnterpriseOne é a disciplina que transforma essa pergunta de uma análise forense de vários dias em uma consulta que retorna em segundos. A maioria das instalações tem entre 80 e 400 business views custom sobrepostas a tabelas standard e custom, chamadas por um número desconhecido de aplicações, UBEs e forms — e ninguém tem uma visão atual de quem depende de quem.
O custo de não saber é pago toda vez que algo muda. Uma coluna adicionada à F4211. Um novo índice na F0911. Uma tabela custom renomeada durante uma limpeza. Cada mudança se propaga por qualquer business view que referencie o objeto afetado, e cada BV afeta toda aplicação construída sobre ela. Sem um mapa, o impacto é descoberto quando algo quebra em PY, ou pior, em PD.
Por que business views são o lugar certo para ancorar o mapa
Uma business view no JDE não é uma view de banco de dados. É um objeto de metadados que seleciona colunas de uma ou mais tabelas, define joins entre elas e expõe o resultado como um único dataset retangular ao qual forms, aplicações e UBEs se vinculam. A BV fica entre as tabelas e o código, exatamente por isso é o nó certo para servir como âncora de qualquer mapa de dependências.
Ancorar apenas em tabelas produz ruído — toda aplicação lê tabelas, direta ou indiretamente, e o grafo resultante é denso demais para ser útil. Ancorar em aplicações produz lacunas — aplicações chamam BVs que fazem join entre várias tabelas, e uma pergunta em nível de tabela roteada por um mapa apenas de aplicações perde fidelidade. A BV é o ponto de junção natural: sabe quais tabelas toca e é conhecida por todo chamador acima dela.
No lado upstream, cada BV declara suas tabelas de origem na spec, registrada na tabela de repository F98711Tabela de metadados de colunas de business views — a tabela de repository JDE que registra quais colunas de quais tabelas cada business view expõe, junto com as definições de join.. No lado downstream, cada form, aplicação e UBE que usa uma BV registra a relação na F9860 com um source type que identifica o consumidor. Duas consultas SQL, corretamente unidas, produzem o grafo completo para toda a instalação.
O outro motivo para ancorar em BVs é que elas mudam com menos frequência do que o código que as utiliza. Uma BV com vinte consumidores pode ser modificada uma vez por ano; as vinte aplicações acima dela podem ser alteradas vinte vezes no mesmo período. Um mapa construído sobre a camada estável mantém sua precisão por mais tempo entre ciclos de regeneração.
As tabelas de repository que contêm a verdade
O repository JDE — os metadados sobre cada objeto da instalação — vive em um pequeno conjunto de tabelas de sistema que são read-only do ponto de vista do desenvolvedor e consistentemente subutilizadas para análise. As quatro que importam para mapeamento de dependências são F9860, F98711, F98712 e F98750.
F9860 é o object librarian master. Cada BSFN, aplicação, UBE, business view e tabela tem uma linha aqui, com OBNM (object name), FUNO (function use, que identifica o tipo) e SRCTYPE (source type, distinguindo BV de APPL, UBE e TBL). Uma consulta simples contra F9860 filtrada para os valores FUNO de business views retorna a lista completa de BVs na instalação; filtrada para aplicações, a lista completa de forms acima delas. Os valores de filtro são documentados nas definições de tabelas standard e não mudam entre Tools Releases.
F98711 é a tabela de join em nível de coluna para business views. Cada coluna que uma BV expõe é uma linha, com a tabela de origem e o campo de origem. Agregar F98711 por nome de BV fornece a pegada completa de cada view em nível de tabela — exatamente o que o lado upstream do mapa de dependências precisa.
F98712 registra seções de forms e relatórios que se vinculam a uma BV. Uma aplicação custom que chama três BVs diferentes em seus forms produz três linhas na F98712, indexadas pelo nome da aplicação e pelo nome da BV. Esse é o lado downstream: quais chamadores usam quais views.
F98750 é o armazenamento de dados de spec em Tools Releases modernas — o conteúdo binário das specs é armazenado aqui, indexado por objeto. Para mapeamento de dependências, F98750 normalmente não é a fonte primária porque os metadados legíveis já estão nas outras três tabelas; F98750 só se torna relevante ao perseguir detalhes em nível de spec que as tabelas de metadados achatam.
Construir o grafo: do extract SQL à estrutura navegável
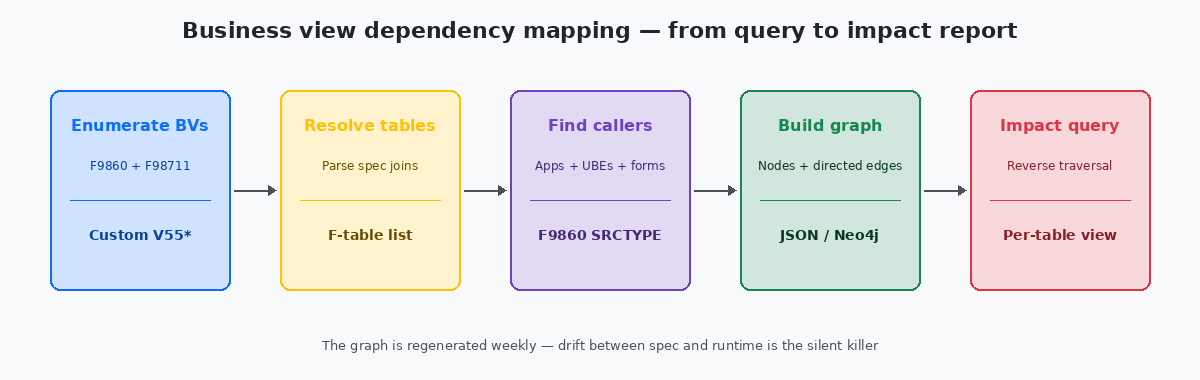
A parte mecânica do mapeamento é direta e frequentemente complicada sem necessidade. Três consultas SQL contra o repository, executadas em sequência, produzem tudo o que é necessário para um grafo completo de dependências para uma instalação de qualquer tamanho.
A primeira consulta enumera cada business view custom — filtrada por prefixo de nome, normalmente V55 a V59 em ambientes que seguem a convenção de namespace reservado da Oracle. A saída é uma lista simples com nome da BV, descrição da BV e timestamp da última modificação. Em uma instalação típica de médio porte, isso retorna de 80 a 300 linhas em menos de um segundo.
A segunda consulta resolve cada BV para suas tabelas de origem. Fazer join de F9860 com F98711 por OBNM e agrupar pela BV mais o nome da tabela de origem produz uma lista many-to-one — uma linha por relação BV-tabela. Uma BV que faz join entre F4211 e F4101 produz duas linhas. Uma BV que toca oito tabelas produz oito. O volume total em uma instalação real geralmente fica entre 200 e 1.500 linhas.
A terceira consulta encontra cada chamador de cada BV lendo F98712 e fazendo join de volta com F9860 para enriquecer o chamador com seu tipo e descrição. Essa é a maior das três saídas, porque uma BV popular pode ter vinte ou trinta chamadores; contagens totais de linhas chegam a milhares em instalações maiores, mas ainda são volumes triviais para qualquer banco de dados moderno.
Os três conjuntos de resultados viram as arestas de um grafo direcionado: tabelas apontam para cima em direção às BVs, BVs apontam para cima em direção aos chamadores. Armazenado como JSON, o grafo cabe em algumas centenas de kilobytes e pode ser carregado em qualquer ferramenta de visualização, de Neo4jUm banco de dados de grafos amplamente usado para análise de dependências, redes e relacionamentos. Armazena nós e arestas direcionadas nativamente e responde a consultas de alcançabilidade com instruções Cypher únicas. até uma página HTML estática com uma biblioteca de layout force-directed. A visualização importa menos do que a estrutura subjacente — o mesmo JSON responde a consultas programáticas tão bem quanto a visuais.
As consultas de impacto que justificam o esforço
Um grafo de dependências que nunca é consultado é teatro de documentação. As consultas que justificam construí-lo são as que respondem a perguntas reais que desenvolvedores e equipes CNC fazem sob pressão.
A primeira consulta de impacto é uma travessia reversa a partir de uma tabela: dado que a F4211 ganhará uma coluna no próximo sprint, listar cada BV custom que seleciona dela e, para cada BV, listar cada chamador. A resposta orienta o plano de testes de regressão. Em um grafo com 200 BVs e 2.000 chamadores, essa consulta retorna em dezenas de milissegundos e produz uma lista exaustiva de um jeito que nenhuma planilha jamais foi.
A segunda consulta de impacto é uma travessia direta a partir de uma aplicação: dado que a custom P55020A está prestes a ser descontinuada, listar cada BV que ela usa e, para cada BV, verificar se algum outro chamador depende dela. Views sem outro consumidor tornam-se candidatas à descontinuação também, e a cadeia continua até tabelas que nada mais lê. Essa é a consulta que impulsiona a limpeza de débito técnico — os candidatos aparecem sozinhos quando o grafo existe.
A terceira consulta é detecção de órfãos. BVs custom na F9860 que têm zero linhas na F98712 são órfãs — existem no repository, mas nada as chama. Tabelas custom das quais nenhuma BV seleciona são órfãs mais profundas. Em uma instalação de 20 anos, as contagens de órfãos geralmente ficam entre 5% e 15% do estate custom, e cada órfão é código morto que ainda precisa ser carregado por todo upgrade. Torná-los visíveis é o primeiro uso prático do grafo na maioria das instalações.

Manter o mapa honesto: cadência de regeneração e drift
O único modo de falha de qualquer mapa de dependências é ficar desatualizado. Um grafo gerado uma vez no início de um projeto e nunca atualizado fica errado em poucas semanas — cada check-in no OMW que adiciona ou modifica uma BV cria um delta que o grafo estático não conhece. A disciplina que mantém o mapa honesto é regeneração automatizada em uma cadência que a equipe realmente segue.
A cadência que funciona na maioria das instalações é semanal. Um job agendado — um shell script, uma pequena UBE ou um script Python conectado ao banco JDE — executa as três consultas de repository, constrói o JSON, arquiva a versão anterior e publica o novo grafo no local usado pela equipe. Semanal é frequente o suficiente para que o mapa nunca fique mais do que alguns dias atrás da realidade, e pouco frequente o suficiente para que o job não gere ruído.
O diff entre snapshots consecutivos é mais útil do que qualquer snapshot isolado. Novas BVs que apareceram nesta semana, BVs cujas tabelas de origem mudaram, BVs que ganharam ou perderam chamadores — esses são os itens que valem ser destacados na revisão semanal da equipe. Uma BV que de repente ganhou uma quinta tabela em seu join é uma oportunidade de code review; uma BV que perdeu seu último chamador restante é candidata à exclusão. O diff tem vinte linhas de script e converte o grafo de um documento de referência em um loop de feedback sobre o que a equipe está realmente construindo.
Para mais contexto, os artigos relacionados sobre retrofit de cópias de standard, escopo de upgrades de Tools Release e estratégias de arquivamento de tabelas F cobrem a camada operacional sobre a qual este mapa se apoia. O portfólio de projetos técnicos deste site documenta duas ferramentas de dependência em produção que produziram os padrões descritos aqui.