Sélectionnez votre langue
Mon blog

- Détails
- By Vincenzo Caserta
- Catégorie : Mon blog
Des données de télémétrie récentes datant de 2026 suggèrent que le serveur web d’entreprise moyen génère désormais plus de 1,2 téraoctet de données de logs par mois, un volume qui rend l’inspection manuelle non seulement inefficace, mais mathématiquement impossible pour des opérateurs humains. À l’heure où les microservicesUn style architectural qui structure une application comme un ensemble de petits services autonomes, organisés autour d’un domaine métier. dominent le paysage, le simple log Nginx est passé du statut de fichier texte à celui de flux critique de données à haute vélocité. Pourtant, de nombreux administrateurs restent attachés à des processus manuels archaïques, incapables de capter le véritable pouls de leur infrastructure. Comprendre comment automatiser la gestion des logs Nginx n’est plus un luxe ; c’est une exigence fondamentale pour préserver l’intégrité et les performances des systèmes dans un monde hyperconnecté.
- Détails
- By Vincenzo Caserta
- Catégorie : Mon blog
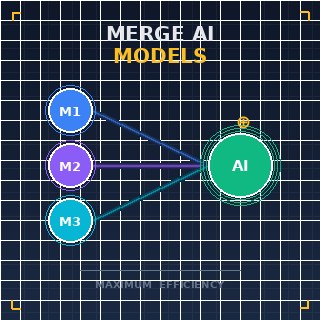
Dans un laboratoire de haute technologie à Zurich, un data scientist fixe un écran de terminal où deux esprits neuronaux distincts sont sur le point de ne faire qu'un. L'un des modèles est un maître de la biologie moléculaire, tandis que l'autre est un expert en dynamique des fluides ; séparément, ils sont brillants, mais ensemble, ils pourraient révolutionner les systèmes d'administration de médicaments. C'est la réalité de 2026, où le défi principal n'est plus seulement de construire des systèmes plus vastes, mais de trouver comment fusionner plusieurs Large Language Models (LLMs)Systèmes d'intelligence artificielle entraînés sur de vastes quantités de texte pour comprendre et générer un langage humain. en une intelligence unique et cohérente. Ce processus, connu sous le nom de fusion de modèles (model merging), est passé d'une curiosité expérimentale à une norme d'ingénierie critique, permettant aux développeurs de synthétiser les forces de diverses architectures sans les coûts prohibitifs d'un réentraînement complet.

- Détails
- By Vincenzo Caserta
- Catégorie : Mon blog
Imaginez un chercheur en génomique en 2026 tentant d'isoler un seul variant de protéine parmi une bibliothèque de cinquante mille entrées à l'aide d'un élément HTML select standard. Le navigateur se fige, la barre de défilement devient microscopique et l'expérience utilisateur s'effondre sous le poids excessif des nœuds DOMLe Document Object Model est une interface de programmation pour les documents web, représentant la page afin que les programmes puissent en modifier la structure et le contenu.. Pour résoudre ce problème, nous devons dépasser les éléments statiques et adopter des composants programmables. Apprendre à créer une liste déroulante dynamique avec recherche n'est plus seulement une préférence UI/UXLa conception de l'interface utilisateur et de l'expérience utilisateur se concentre sur les aspects esthétiques et fonctionnels de l'interaction humaine avec les logiciels. ; c'est une nécessité technique pour la gestion de données haute performance et les plateformes de visualisation scientifique.

- Détails
- By Vincenzo Caserta
- Catégorie : Mon blog
Pourquoi nos modèles prédictifs les plus avancés, bien qu'entraînés sur le matériel le plus coûteux disponible en 2026, s'effondrent-ils encore face à un changement mineur de contexte environnemental ? Cet échec n'est pas un bug logiciel, mais une inévitabilité mathématique : l'incapacité des architectures actuelles à migrer avec succès la JD (distributions conjointes) d'un domaine source vers un domaine cible. Alors que nous repoussons les limites des systèmes autonomes et de la modélisation scientifique en temps réel, l'industrie a enfin reconnu que les données ne sont pas une ressource statique. Pour maintenir la précision, nous devons traiter les données comme une entité fluide nécessitant des stratégies de translocation sophistiquées. Comprendre comment migrer la JD n'est plus un exercice académique ; c'est la pierre angulaire d'une intelligence artificielle robuste.
Plus d'articles...
Page 1 sur 18